 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Conditional Alignment based on Label Shift Calibration for Imbalanced Domain Adaptation
Dec 29, 2024Many existing unsupervised domain adaptation (UDA) methods primarily focus on covariate shift, limiting their effectiveness in imbalanced domain adaptation (IDA) where both covariate shift and label shift coexist. Recent IDA methods have achieved promising results based on self-training using target pseudo labels. However, under the IDA scenarios, the classifier learned in the source domain will exhibit different decision bias from the target domain. It will potentially make target pseudo labels unreliable, and will further lead to error accumulation with incorrect class alignment. Thus, we propose contrastive conditional alignment based on label shift calibration (CCA-LSC) for IDA, to address both covariate shift and label shift. Initially, our contrastive conditional alignment resolve covariate shift to learn representations with domain invariance and class discriminability, which include domain adversarial learning, sample-weighted moving average centroid alignment and discriminative feature alignment. Subsequently, we estimate the probability distribution of the target domain, and calibrate target sample classification predictions based on label shift metrics to encourage labeling pseudo-labels more consistently with the distribution of real target data. Extensive experiments are conducted and demonstrate that our method outperforms existing UDA and IDA methods on benchmarks with both label shift and covariate shift. Our code is available at https://github.com/ysxcj-hub/CCA-LSC.
centroIDA: Cross-Domain Class Discrepancy Minimization Based on Accumulative Class-Centroids for Imbalanced Domain Adaptation
Aug 21, 2023Unsupervised Domain Adaptation (UDA) approaches address the covariate shift problem by minimizing the distribution discrepancy between the source and target domains, assuming that the label distribution is invariant across domains. However, in the imbalanced domain adaptation (IDA) scenario, covariate and long-tailed label shifts both exist across domains. To tackle the IDA problem, some current research focus on minimizing the distribution discrepancies of each corresponding class between source and target domains. Such methods rely much on the reliable pseudo labels' selection and the feature distributions estimation for target domain, and the minority classes with limited numbers makes the estimations more uncertainty, which influences the model's performance. In this paper, we propose a cross-domain class discrepancy minimization method based on accumulative class-centroids for IDA (centroIDA). Firstly, class-based re-sampling strategy is used to obtain an unbiased classifier on source domain. Secondly, the accumulative class-centroids alignment loss is proposed for iterative class-centroids alignment across domains. Finally, class-wise feature alignment loss is used to optimize the feature representation for a robust classification boundary. A series of experiments have proved that our method outperforms other SOTA methods on IDA problem, especially with the increasing degree of label shift.
Dual-Branch Temperature Scaling Calibration for Long-Tailed Recognition
Aug 16, 2023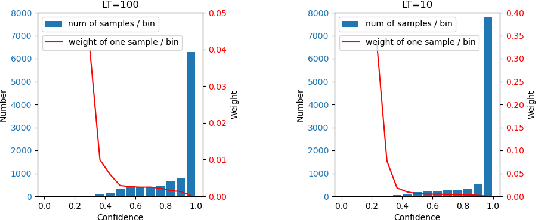

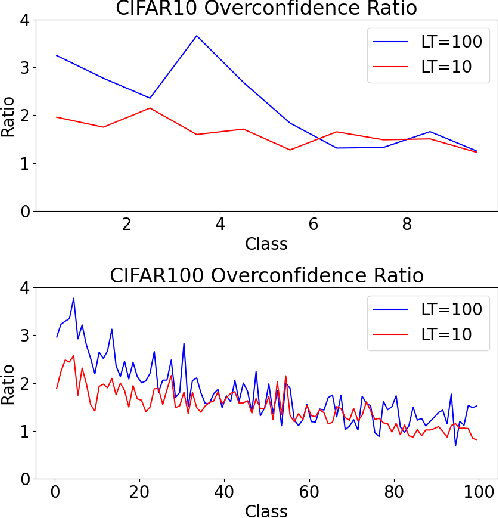

The calibration for deep neural networks is currently receiving widespread attention and research. Miscalibration usually leads to overconfidence of the model. While, under the condition of long-tailed distribution of data, the problem of miscalibration is more prominent due to the different confidence levels of samples in minority and majority categories, and it will result in more serious overconfidence. To address this problem, some current research have designed diverse temperature coefficients for different categories based on temperature scaling (TS) method. However, in the case of rare samples in minority classes, the temperature coefficient is not generalizable, and there is a large difference between the temperature coefficients of the training set and the validation set. To solve this challenge, this paper proposes a dual-branch temperature scaling calibration model (Dual-TS), which considers the diversities in temperature parameters of different categories and the non-generalizability of temperature parameters for rare samples in minority classes simultaneously. Moreover, we noticed that the traditional calibration evaluation metric, Excepted Calibration Error (ECE), gives a higher weight to low-confidence samples in the minority classes, which leads to inaccurate evaluation of model calibration. Therefore, we also propose Equal Sample Bin Excepted Calibration Error (Esbin-ECE) as a new calibration evaluation metric. Through experiments, we demonstrate that our model yields state-of-the-art in both traditional ECE and Esbin-ECE metrics.
A New Data Normalization Method to Improve Dialogue Generation by Minimizing Long Tail Effect
May 04, 2020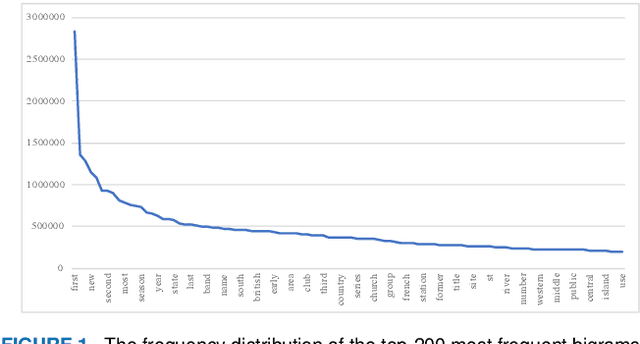
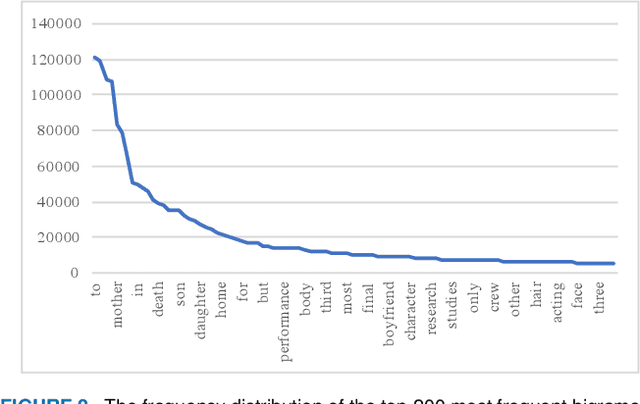

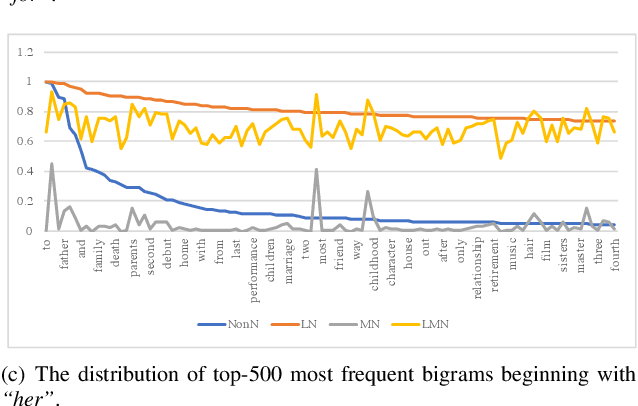
Recent neural models have shown significant progress in dialogue generation. Most generation models are based on language models. However, due to the Long Tail Phenomenon in linguistics, the trained models tend to generate words that appear frequently in training datasets, leading to a monotonous issue. To address this issue, we analyze a large corpus from Wikipedia and propose three frequency-based data normalization methods. We conduct extensive experiments based on transformers and three datasets respectively collected from social media, subtitles, and the industrial application. Experimental results demonstrate significant improvements in diversity and informativeness (defined as the numbers of nouns and verbs) of generated responses. More specifically, the unigram and bigram diversity are increased by 2.6%-12.6% and 2.2%-18.9% on the three datasets, respectively. Moreover, the informativeness, i.e. the numbers of nouns and verbs, are increased by 4.0%-7.0% and 1.4%-12.1%, respectively. Additionally, the simplicity and effectiveness enable our methods to be adapted to different generation models without much extra computational cost.