 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Symptoms and How Long? An Interpretable AI Approach for Depression Detection in Social Media
May 18, 2023Depression is the most prevalent and serious mental illness, which induces grave financial and societal ramifications. Depression detection is key for early intervention to mitigate those consequences. Such a high-stake decision inherently necessitates interpretability, which most existing methods fall short of. To connect human expertise in this decision-making, safeguard trust from end users, and ensure algorithm transparency, we develop an interpretable deep learning model: Multi-Scale Temporal Prototype Network (MSTPNet). MSTPNet is built upon the emergent prototype learning methods. In line with the medical practice of depression diagnosis, MSTPNet differs from existing prototype learning models in its capability of capturing the depressive symptoms and their temporal distribution such as frequency and persistence of appearance. Extensive empirical analyses using real-world social media data show that MSTPNet outperforms state-of-the-art benchmarks in depression detection, with an F1-score of 0.851. Moreover, MSTPNet interprets its prediction by identifying what depression symptoms the user presents and how long these related symptoms last. We further conduct a user study to demonstrate its superiority over the benchmarks in interpretability. Methodologically, this study contributes to extant literature with a novel interpretable deep learning model for depression detection in social media. Our proposed method can be implemented in social media platforms to detect depression and its symptoms. Platforms can subsequently provide personalized online resources such as educational and supporting videos and articles, or sources for treatments and social support for depressed patients.
IGN : Implicit Generative Networks
Jun 13, 2022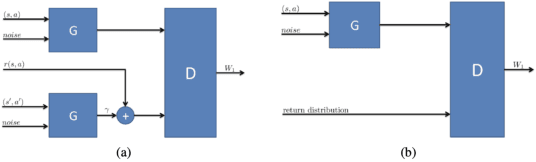
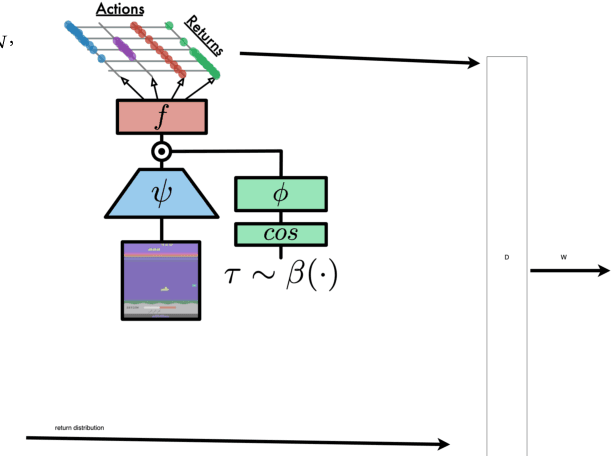
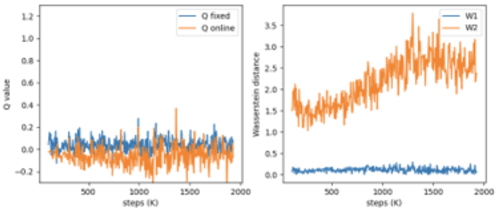
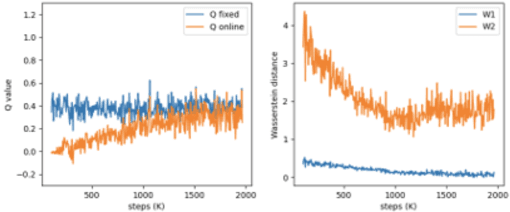
In this work, we build recent advances in distributional reinforcement learning to give a state-of-art distributional variant of the model based on the IQN. We achieve this by using the GAN model's generator and discriminator function with the quantile regression to approximate the full quantile value for the state-action return distribution. We demonstrate improved performance on our baseline dataset - 57 Atari 2600 games in the ALE. Also, we use our algorithm to show the state-of-art training performance of risk-sensitive policies in Atari games with the policy optimization and evaluation.