Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGN : Implicit Generative Networks
Jun 13, 2022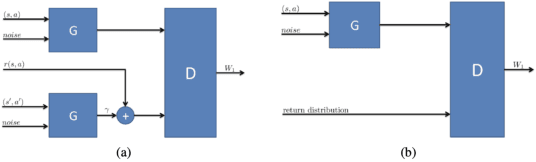
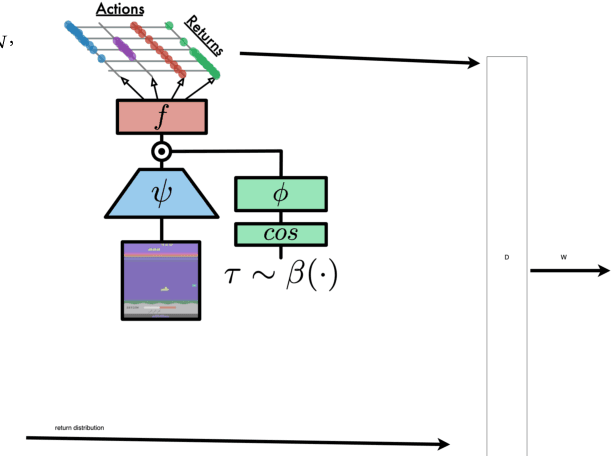
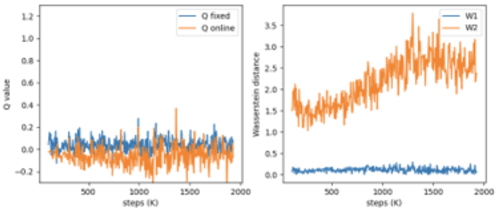
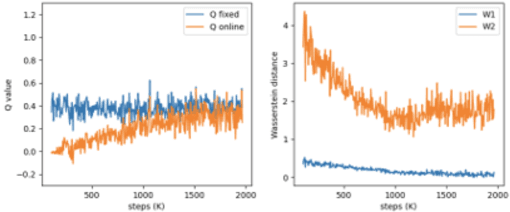
In this work, we build recent advances in distributional reinforcement learning to give a state-of-art distributional variant of the model based on the IQN. We achieve this by using the GAN model's generator and discriminator function with the quantile regression to approximate the full quantile value for the state-action return distribution. We demonstrate improved performance on our baseline dataset - 57 Atari 2600 games in the ALE. Also, we use our algorithm to show the state-of-art training performance of risk-sensitive policies in Atari games with the policy optimization and evaluation.
Via