 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Basis Path Set in Neural Networks
Oct 18, 2019

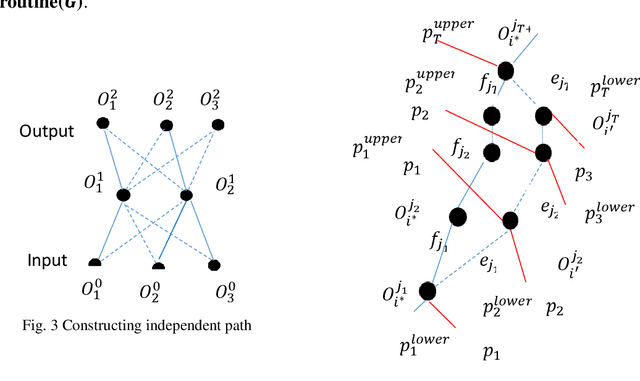

Based on basis path set, G-SGD algorithm significantly outperforms conventional SGD algorithm in optimizing neural networks. However, how the inner mechanism of basis paths work remains mysterious. From the aspect of graph theory, this paper defines basis path, investigates structure properties of basis paths in regular fully connected neural network and interprets the graph representation of basis path set. Moreover, we propose hierarchical algorithm HBPS to find basis path set B in fully connected neural network by decomposing the network into several independent and parallel substructures. Algorithm HBPS demands that there doesn't exist shared edges between any two independent substructure paths.
Positively Scale-Invariant Flatness of ReLU Neural Networks
Mar 06, 2019

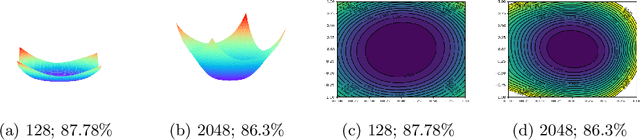
It was empirically confirmed by Keskar et al.\cite{SharpMinima} that flatter minima generalize better. However, for the popular ReLU network, sharp minimum can also generalize well \cite{SharpMinimacan}. The conclusion demonstrates that the existing definitions of flatness fail to account for the complex geometry of ReLU neural networks because they can't cover the Positively Scale-Invariant (PSI) property of ReLU network. In this paper, we formalize the PSI causes problem of existing definitions of flatness and propose a new description of flatness - \emph{PSI-flatness}. PSI-flatness is defined on the values of basis paths \cite{GSGD} instead of weights. Values of basis paths have been shown to be the PSI-variables and can sufficiently represent the ReLU neural networks which ensure the PSI property of PSI-flatness. Then we study the relation between PSI-flatness and generalization theoretically and empirically. First, we formulate a generalization bound based on PSI-flatness which shows generalization error decreasing with the ratio between the largest basis path value and the smallest basis path value. That is to say, the minimum with balanced values of basis paths will more likely to be flatter and generalize better. Finally. we visualize the PSI-flatness of loss surface around two learned models which indicates the minimum with smaller PSI-flatness can indeed generalize better.