 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI-Light: Physics-Inspired Diffusion for Full-Image Relighting
Jan 29, 2026Full-image relighting remains a challenging problem due to the difficulty of collecting large-scale structured paired data, the difficulty of maintaining physical plausibility, and the limited generalizability imposed by data-driven priors. Existing attempts to bridge the synthetic-to-real gap for full-scene relighting remain suboptimal. To tackle these challenges, we introduce Physics-Inspired diffusion for full-image reLight ($π$-Light, or PI-Light), a two-stage framework that leverages physics-inspired diffusion models. Our design incorporates (i) batch-aware attention, which improves the consistency of intrinsic predictions across a collection of images, (ii) a physics-guided neural rendering module that enforces physically plausible light transport, (iii) physics-inspired losses that regularize training dynamics toward a physically meaningful landscape, thereby enhancing generalizability to real-world image editing, and (iv) a carefully curated dataset of diverse objects and scenes captured under controlled lighting conditions. Together, these components enable efficient finetuning of pretrained diffusion models while also providing a solid benchmark for downstream evaluation. Experiments demonstrate that $π$-Light synthesizes specular highlights and diffuse reflections across a wide variety of materials, achieving superior generalization to real-world scenes compared with prior approaches.
Control Color: Multimodal Diffusion-based Interactive Image Colorization
Feb 16, 2024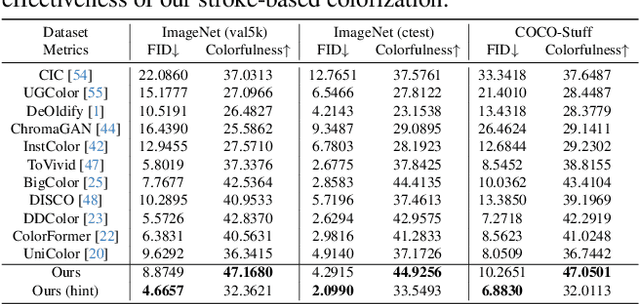



Despite the existence of numerous colorization methods, several limitations still exist, such as lack of user interaction, inflexibility in local colorization, unnatural color rendering, insufficient color variation, and color overflow. To solve these issues, we introduce Control Color (CtrlColor), a multi-modal colorization method that leverages the pre-trained Stable Diffusion (SD) model, offering promising capabilities in highly controllable interactive image colorization. While several diffusion-based methods have been proposed, supporting colorization in multiple modalities remains non-trivial. In this study, we aim to tackle both unconditional and conditional image colorization (text prompts, strokes, exemplars) and address color overflow and incorrect color within a unified framework. Specifically, we present an effective way to encode user strokes to enable precise local color manipulation and employ a practical way to constrain the color distribution similar to exemplars. Apart from accepting text prompts as conditions, these designs add versatility to our approach. We also introduce a novel module based on self-attention and a content-guided deformable autoencoder to address the long-standing issues of color overflow and inaccurate coloring. Extensive comparisons show that our model outperforms state-of-the-art image colorization methods both qualitatively and quantitatively.
Iterative Prompt Learning for Unsupervised Backlit Image Enhancement
Mar 30, 2023We propose a novel unsupervised backlit image enhancement method, abbreviated as CLIP-LIT, by exploring the potential of Contrastive Language-Image Pre-Training (CLIP) for pixel-level image enhancement. We show that the open-world CLIP prior not only aids in distinguishing between backlit and well-lit images, but also in perceiving heterogeneous regions with different luminance, facilitating the optimization of the enhancement network. Unlike high-level and image manipulation tasks, directly applying CLIP to enhancement tasks is non-trivial, owing to the difficulty in finding accurate prompts. To solve this issue, we devise a prompt learning framework that first learns an initial prompt pair by constraining the text-image similarity between the prompt (negative/positive sample) and the corresponding image (backlit image/well-lit image) in the CLIP latent space. Then, we train the enhancement network based on the text-image similarity between the enhanced result and the initial prompt pair. To further improve the accuracy of the initial prompt pair, we iteratively fine-tune the prompt learning framework to reduce the distribution gaps between the backlit images, enhanced results, and well-lit images via rank learning, boosting the enhancement performance. Our method alternates between updating the prompt learning framework and enhancement network until visually pleasing results are achieved. Extensive experiments demonstrate that our method outperforms state-of-the-art methods in terms of visual quality and generalization ability, without requiring any paired data.
Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
Feb 23, 2023Ultra-High-Definition (UHD) photo has gradually become the standard configuration in advanced imaging devices. The new standard unveils many issues in existing approaches for low-light image enhancement (LLIE), especially in dealing with the intricate issue of joint luminance enhancement and noise removal while remaining efficient. Unlike existing methods that address the problem in the spatial domain, we propose a new solution, UHDFour, that embeds Fourier transform into a cascaded network. Our approach is motivated by a few unique characteristics in the Fourier domain: 1) most luminance information concentrates on amplitudes while noise is closely related to phases, and 2) a high-resolution image and its low-resolution version share similar amplitude patterns.Through embedding Fourier into our network, the amplitude and phase of a low-light image are separately processed to avoid amplifying noise when enhancing luminance. Besides, UHDFour is scalable to UHD images by implementing amplitude and phase enhancement under the low-resolution regime and then adjusting the high-resolution scale with few computations. We also contribute the first real UHD LLIE dataset, \textbf{UHD-LL}, that contains 2,150 low-noise/normal-clear 4K image pairs with diverse darkness and noise levels captured in different scenarios. With this dataset, we systematically analyze the performance of existing LLIE methods for processing UHD images and demonstrate the advantage of our solution. We believe our new framework, coupled with the dataset, would push the frontier of LLIE towards UHD. The code and dataset are available at https://li-chongyi.github.io/UHDFour.
* Porject page: https://li-chongyi.github.io/UHDFour
Fancy Man Lauches Zippo at WNUT 2020 Shared Task-1: A Bert Case Model for Wet Lab Entity Extraction
Sep 28, 2020


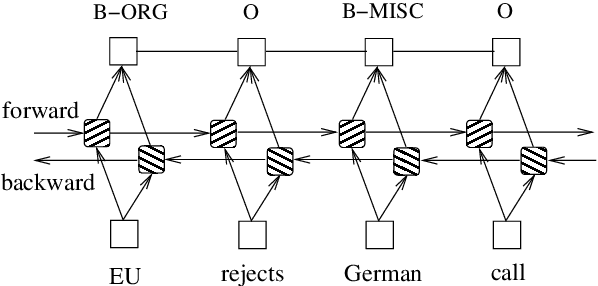
Automatic or semi-automatic conversion of protocols specifying steps in performing a lab procedure into machine-readable format benefits biological research a lot. These noisy, dense, and domain-specific lab protocols processing draws more and more interests with the development of deep learning. This paper presents our teamwork on WNUT 2020 shared task-1: wet lab entity extract, that we conducted studies in several models, including a BiLSTM CRF model and a Bert case model which can be used to complete wet lab entity extraction. And we mainly discussed the performance differences of \textbf{Bert case} under different situations such as \emph{transformers} versions, case sensitivity that may don't get enough attention before.