 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Model Training by Low-Rank Projection with Energy Transfer
Apr 12, 2022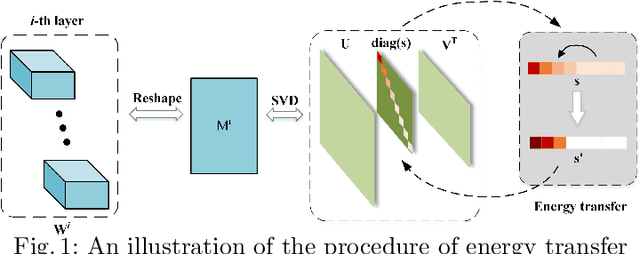
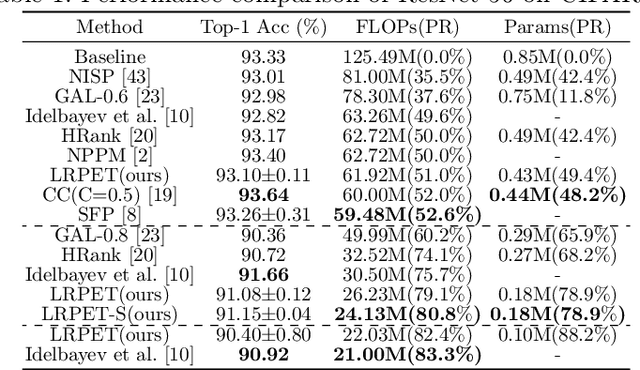
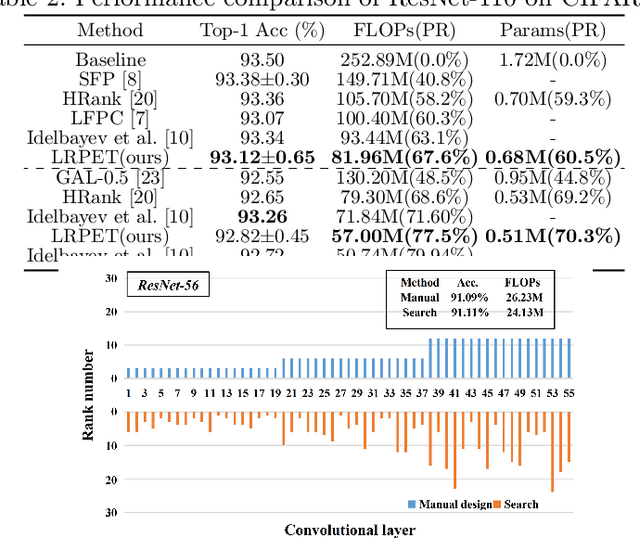
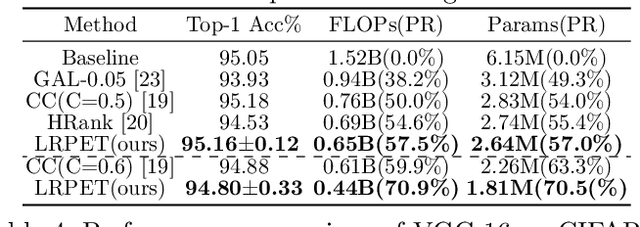
Low-rankness plays an important role in traditional machine learning, but is not so popular in deep learning. Most previous low-rank network compression methods compress the networks by approximating pre-trained models and re-training. However, optimal solution in the Euclidean space may be quite different from the one in the low-rank manifold. A well pre-trained model is not a good initialization for the model with low-rank constraint. Thus, the performance of low-rank compressed network degrades significantly. Compared to other network compression methods such as pruning, low-rank methods attracts less attention in recent years. In this paper, we devise a new training method, low-rank projection with energy transfer (LRPET), that trains low-rank compressed networks from scratch and achieves competitive performance. First, we propose to alternately perform stochastic gradient descent training and projection onto the low-rank manifold. This asymptotically approaches the optimal solution in the low-rank manifold. Compared to re-training on compact model, this enables fully utilization of model capacity since solution space is relaxed back to Euclidean space after projection. Second, the matrix energy (the sum of squares of singular values) reduction caused by projection is compensated by energy transfer. We uniformly transfer the energy of the pruned singular values to the remaining ones. We theoretically show that energy transfer eases the trend of gradient vanishing caused by projection. Comprehensive experiment on CIFAR-10 and ImageNet have justified that our method is superior to other low-rank compression methods and also outperforms recent state-of-the-art pruning methods.
Weight Evolution: Improving Deep Neural Networks Training through Evolving Inferior Weight Values
Oct 09, 2021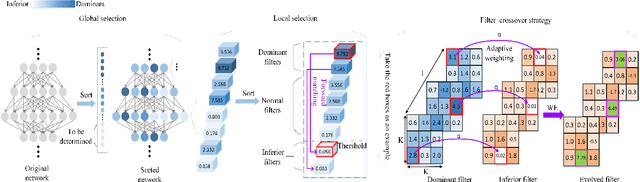


To obtain good performance, convolutional neural networks are usually over-parameterized. This phenomenon has stimulated two interesting topics: pruning the unimportant weights for compression and reactivating the unimportant weights to make full use of network capability. However, current weight reactivation methods usually reactivate the entire filters, which may not be precise enough. Looking back in history, the prosperity of filter pruning is mainly due to its friendliness to hardware implementation, but pruning at a finer structure level, i.e., weight elements, usually leads to better network performance. We study the problem of weight element reactivation in this paper. Motivated by evolution, we select the unimportant filters and update their unimportant elements by combining them with the important elements of important filters, just like gene crossover to produce better offspring, and the proposed method is called weight evolution (WE). WE is mainly composed of four strategies. We propose a global selection strategy and a local selection strategy and combine them to locate the unimportant filters. A forward matching strategy is proposed to find the matched important filters and a crossover strategy is proposed to utilize the important elements of the important filters for updating unimportant filters. WE is plug-in to existing network architectures. Comprehensive experiments show that WE outperforms the other reactivation methods and plug-in training methods with typical convolutional neural networks, especially lightweight networks. Our code is available at https://github.com/BZQLin/Weight-evolution.