 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Spectral Feedback Network for Super-Resolution of Hyperspectral Imagery
Mar 07, 2021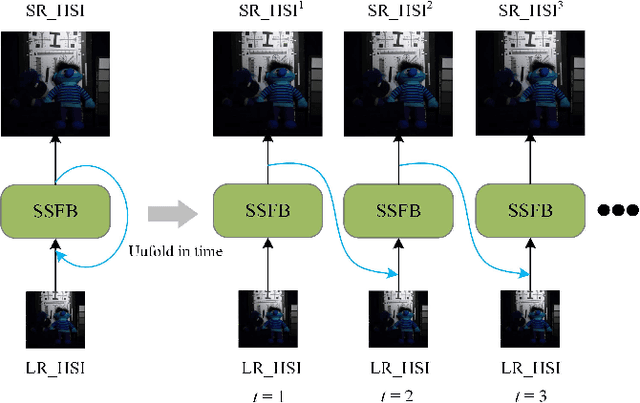
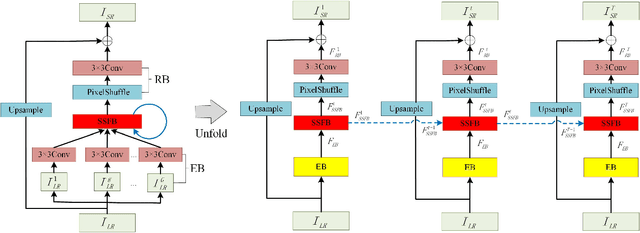
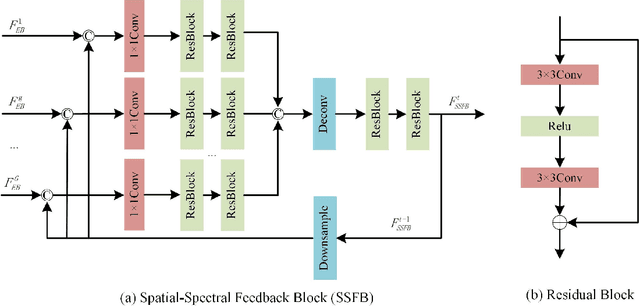
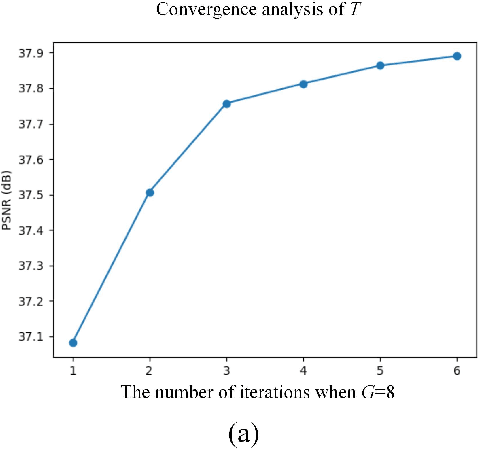
Recently, single gray/RGB image super-resolution (SR) methods based on deep learning have achieved great success. However, there are two obstacles to limit technical development in the single hyperspectral image super-resolution. One is the high-dimensional and complex spectral patterns in hyperspectral image, which make it difficult to explore spatial information and spectral information among bands simultaneously. The other is that the number of available hyperspectral training samples is extremely small, which can easily lead to overfitting when training a deep neural network. To address these issues, in this paper, we propose a novel Spatial-Spectral Feedback Network (SSFN) to refine low-level representations among local spectral bands with high-level information from global spectral bands. It will not only alleviate the difficulty in feature extraction due to high dimensional of hyperspectral data, but also make the training process more stable. Specifically, we use hidden states in an RNN with finite unfoldings to achieve such feedback manner. To exploit the spatial and spectral prior, a Spatial-Spectral Feedback Block (SSFB) is designed to handle the feedback connections and generate powerful high-level representations. The proposed SSFN comes with a early predictions and can reconstruct the final high-resolution hyperspectral image step by step. Extensive experimental results on three benchmark datasets demonstrate that the proposed SSFN achieves superior performance in comparison with the state-of-the-art methods. The source code is available at https://github.com/tangzhenjie/SSFN.
SRDA-Net: Super-Resolution Domain Adaptation Networks for Semantic Segmentation
May 21, 2020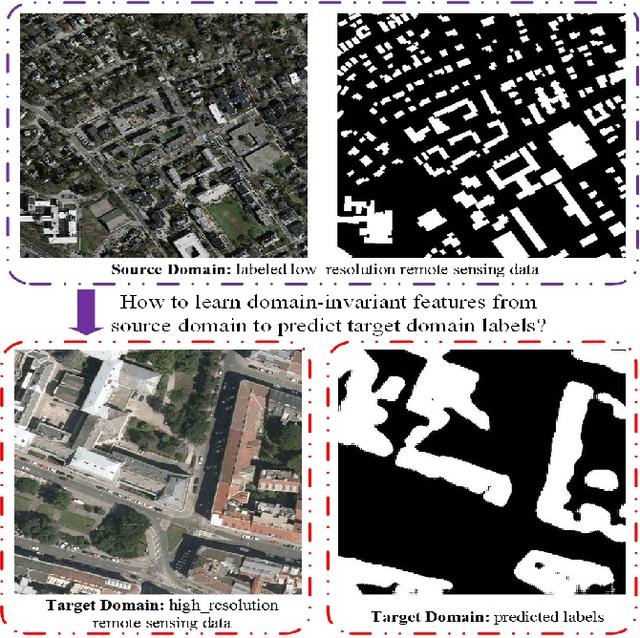
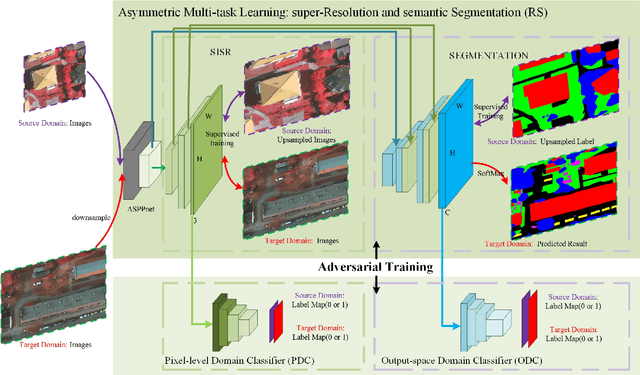

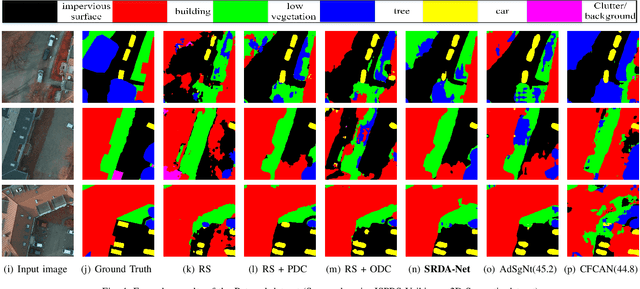
Recently, Unsupervised Domain Adaptation was proposed to address the domain shift problem in semantic segmentation task, but it may perform poor when source and target domains belong to different resolutions. In this work, we design a novel end-to-end semantic segmentation network, Super-Resolution Domain Adaptation Network (SRDA-Net), which could simultaneously complete super-resolution and domain adaptation. Such characteristics exactly meet the requirement of semantic segmentation for remote sensing images which usually involve various resolutions. Generally, SRDA-Net includes three deep neural networks: a Super-Resolution and Segmentation (SRS) model focuses on recovering high-resolution image and predicting segmentation map; a pixel-level domain classifier (PDC) tries to distinguish the images from which domains; and output-space domain classifier (ODC) discriminates pixel label distributions from which domains. PDC and ODC are considered as the discriminators, and SRS is treated as the generator. By the adversarial learning, SRS tries to align the source with target domains on pixel-level visual appearance and output-space. Experiments are conducted on the two remote sensing datasets with different resolutions. SRDA-Net performs favorably against the state-of-the-art methods in terms of accuracy and visual quality. Code and models are available at https://github.com/tangzhenjie/SRDA-Net.