 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Graph in Language Model Rediscovers Cortical Hierarchy in Human Narrative Processing
Nov 17, 2023



Understanding how humans process natural language has long been a vital research direction. The field of natural language processing (NLP) has recently experienced a surge in the development of powerful language models. These models have proven to be invaluable tools for studying another complex system known to process human language: the brain. Previous studies have demonstrated that the features of language models can be mapped to fMRI brain activity. This raises the question: is there a commonality between information processing in language models and the human brain? To estimate information flow patterns in a language model, we examined the causal relationships between different layers. Drawing inspiration from the workspace framework for consciousness, we hypothesized that features integrating more information would more accurately predict higher hierarchical brain activity. To validate this hypothesis, we classified language model features into two categories based on causal network measures: 'low in-degree' and 'high in-degree'. We subsequently compared the brain prediction accuracy maps for these two groups. Our results reveal that the difference in prediction accuracy follows a hierarchical pattern, consistent with the cortical hierarchy map revealed by activity time constants. This finding suggests a parallel between how language models and the human brain process linguistic information.
Spontaneous Emerging Preference in Two-tower Language Model
Oct 13, 2022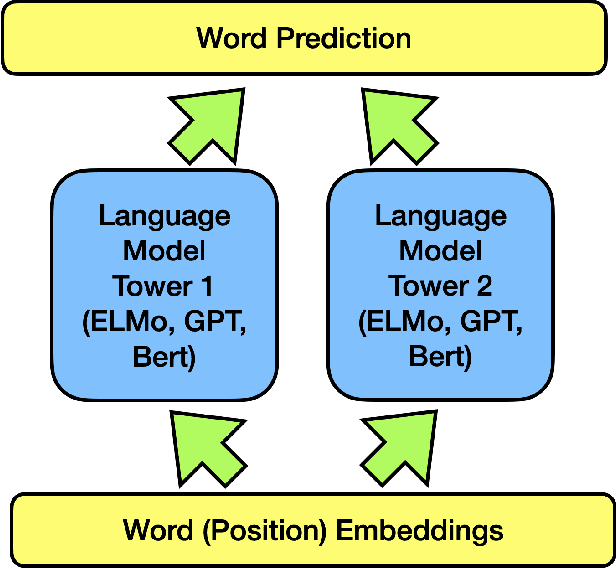
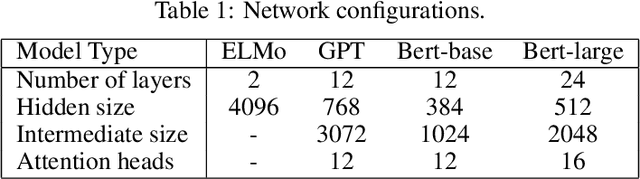
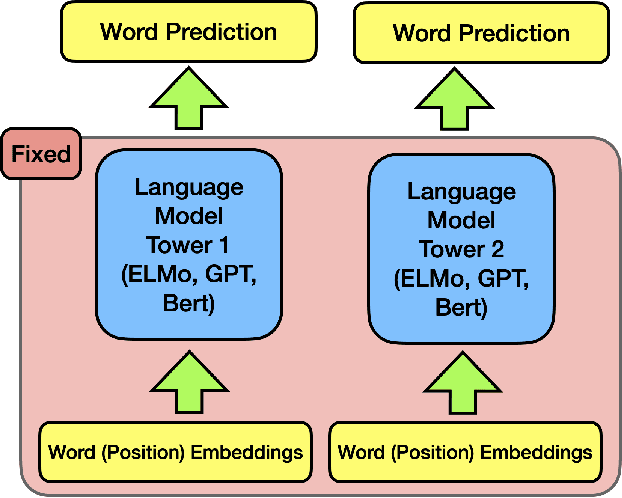
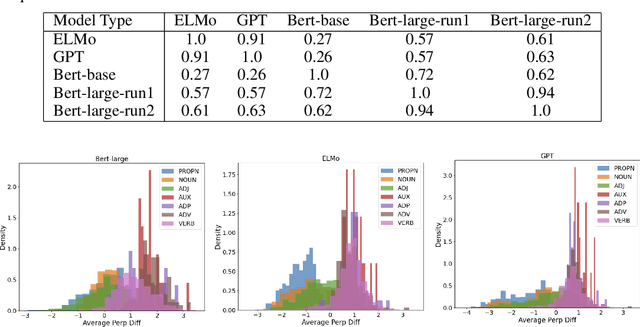
The ever-growing size of the foundation language model has brought significant performance gains in various types of downstream tasks. With the existence of side-effects brought about by the large size of the foundation language model such as deployment cost, availability issues, and environmental cost, there is some interest in exploring other possible directions, such as a divide-and-conquer scheme. In this paper, we are asking a basic question: are language processes naturally dividable? We study this problem with a simple two-tower language model setting, where two language models with identical configurations are trained side-by-side cooperatively. With this setting, we discover the spontaneous emerging preference phenomenon, where some of the tokens are consistently better predicted by one tower while others by another tower. This phenomenon is qualitatively stable, regardless of model configuration and type, suggesting this as an intrinsic property of natural language. This study suggests that interesting properties of natural language are still waiting to be discovered, which may aid the future development of natural language processing techniques.
An Information-theoretic Progressive Framework for Interpretation
Jan 08, 2021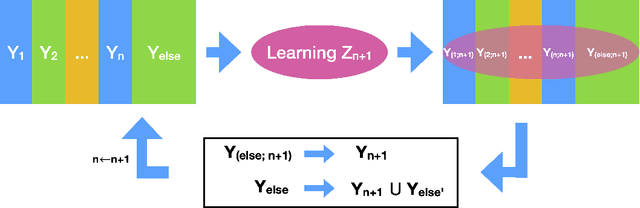
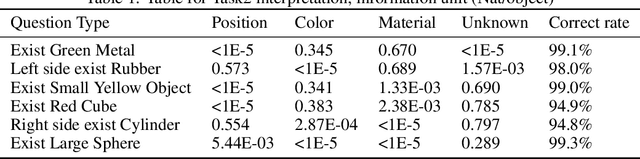
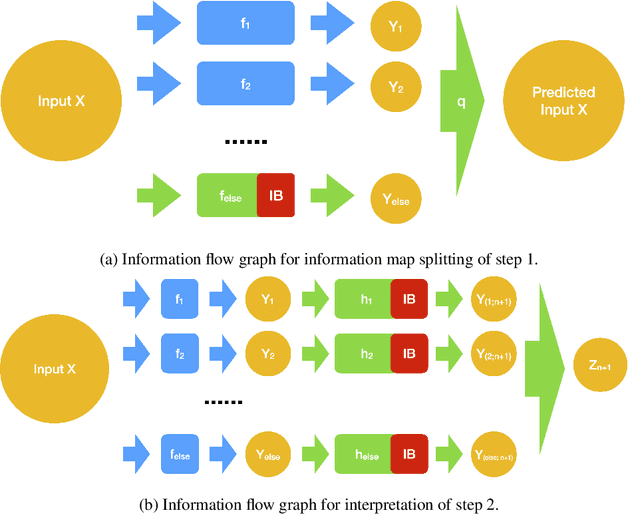
Both brain science and the deep learning communities have the problem of interpreting neural activity. For deep learning, even though we can access all neurons' activity data, interpretation of how the deep network solves the task is still challenging. Although a large amount of effort has been devoted to interpreting a deep network, there is still no consensus of what interpretation is. This paper tries to push the discussion in this direction and proposes an information-theoretic progressive framework to synthesize interpretation. Firstly, we discuss intuitions of interpretation: interpretation is meta-information; interpretation should be at the right level; inducing independence is helpful to interpretation; interpretation is naturally progressive; interpretation doesn't have to involve a human. Then, we build the framework with an information map splitting idea and implement it with the variational information bottleneck technique. After that, we test the framework with the CLEVR dataset. The framework is shown to be able to split information maps and synthesize interpretation in the form of meta-information.