 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHands-on Guidance for Distilling Object Detectors
Mar 26, 2021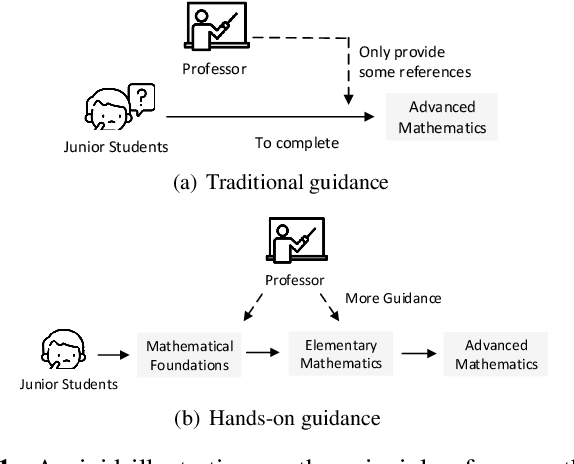
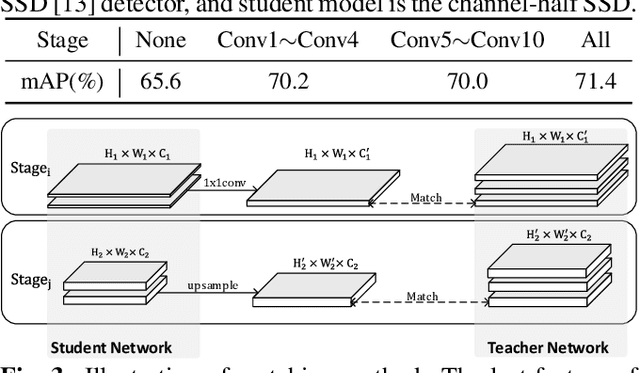
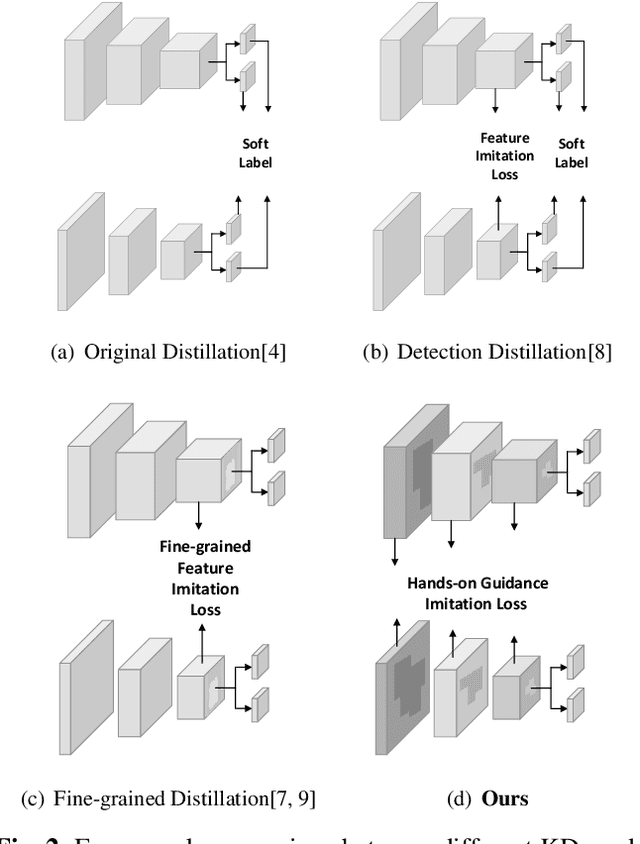
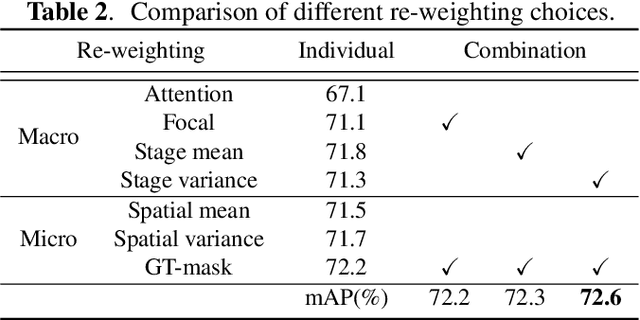
Knowledge distillation can lead to deploy-friendly networks against the plagued computational complexity problem, but previous methods neglect the feature hierarchy in detectors. Motivated by this, we propose a general framework for detection distillation. Our method, called Hands-on Guidance Distillation, distills the latent knowledge of all stage features for imposing more comprehensive supervision, and focuses on the essence simultaneously for promoting more intense knowledge absorption. Specifically, a series of novel mechanisms are designed elaborately, including correspondence establishment for consistency, hands-on imitation loss measure and re-weighted optimization from both micro and macro perspectives. We conduct extensive evaluations with different distillation configurations over VOC and COCO datasets, which show better performance on accuracy and speed trade-offs. Meanwhile, feasibility experiments on different structural networks further prove the robustness of our HGD.