 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Path GMM-ResNet and GMM-SENet for ASV Spoofing Detection
Jul 08, 2024The automatic speaker verification system is sometimes vulnerable to various spoofing attacks. The 2-class Gaussian Mixture Model classifier for genuine and spoofed speech is usually used as the baseline for spoofing detection. However, the GMM classifier does not separately consider the scores of feature frames on each Gaussian component. In addition, the GMM accumulates the scores on all frames independently, and does not consider their correlations. We propose the two-path GMM-ResNet and GMM-SENet models for spoofing detection, whose input is the Gaussian probability features based on two GMMs trained on genuine and spoofed speech respectively. The models consider not only the score distribution on GMM components, but also the relationship between adjacent frames. A two-step training scheme is applied to improve the system robustness. Experiments on the ASVspoof 2019 show that the LFCC+GMM-ResNet system can relatively reduce min-tDCF and EER by 76.1% and 76.3% on logical access scenario compared with the GMM, and the LFCC+GMM-SENet system by 94.4% and 95.4% on physical access scenario. After score fusion, the systems give the second-best results on both scenarios.
GMM-ResNext: Combining Generative and Discriminative Models for Speaker Verification
Jul 03, 2024With the development of deep learning, many different network architectures have been explored in speaker verification. However, most network architectures rely on a single deep learning architecture, and hybrid networks combining different architectures have been little studied in ASV tasks. In this paper, we propose the GMM-ResNext model for speaker verification. Conventional GMM does not consider the score distribution of each frame feature over all Gaussian components and ignores the relationship between neighboring speech frames. So, we extract the log Gaussian probability features based on the raw acoustic features and use ResNext-based network as the backbone to extract the speaker embedding. GMM-ResNext combines Generative and Discriminative Models to improve the generalization ability of deep learning models and allows one to more easily specify meaningful priors on model parameters. A two-path GMM-ResNext model based on two gender-related GMMs has also been proposed. The Experimental results show that the proposed GMM-ResNext achieves relative improvements of 48.1\% and 11.3\% in EER compared with ResNet34 and ECAPA-TDNN on VoxCeleb1-O test set.
GMM-ResNet2: Ensemble of Group ResNet Networks for Synthetic Speech Detection
Jul 02, 2024
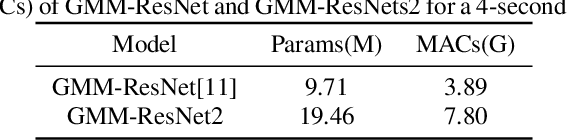

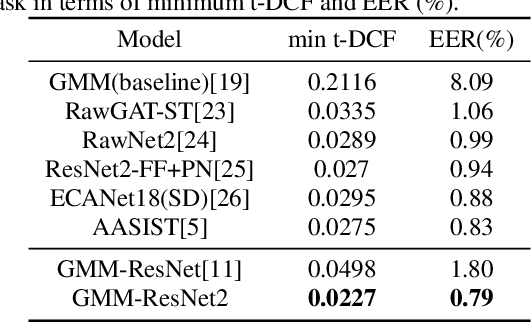
Deep learning models are widely used for speaker recognition and spoofing speech detection. We propose the GMM-ResNet2 for synthesis speech detection. Compared with the previous GMM-ResNet model, GMM-ResNet2 has four improvements. Firstly, the different order GMMs have different capabilities to form smooth approximations to the feature distribution, and multiple GMMs are used to extract multi-scale Log Gaussian Probability features. Secondly, the grouping technique is used to improve the classification accuracy by exposing the group cardinality while reducing both the number of parameters and the training time. The final score is obtained by ensemble of all group classifier outputs using the averaging method. Thirdly, the residual block is improved by including one activation function and one batch normalization layer. Finally, an ensemble-aware loss function is proposed to integrate the independent loss functions of all ensemble members. On the ASVspoof 2019 LA task, the GMM-ResNet2 achieves a minimum t-DCF of 0.0227 and an EER of 0.79\%. On the ASVspoof 2021 LA task, the GMM-ResNet2 achieves a minimum t-DCF of 0.2362 and an EER of 2.19\%, and represents a relative reductions of 31.4\% and 76.3\% compared with the LFCC-LCNN baseline.