 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMM-ResNet2: Ensemble of Group ResNet Networks for Synthetic Speech Detection
Paper and Code
Jul 02, 2024
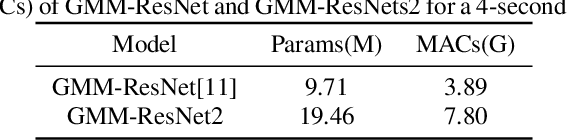

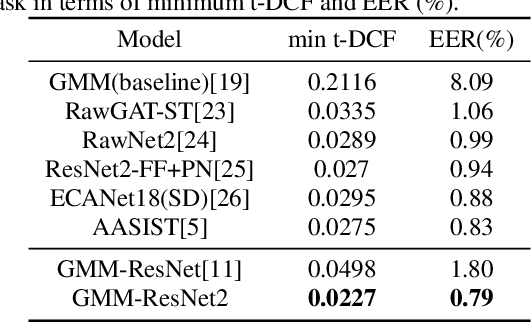
Deep learning models are widely used for speaker recognition and spoofing speech detection. We propose the GMM-ResNet2 for synthesis speech detection. Compared with the previous GMM-ResNet model, GMM-ResNet2 has four improvements. Firstly, the different order GMMs have different capabilities to form smooth approximations to the feature distribution, and multiple GMMs are used to extract multi-scale Log Gaussian Probability features. Secondly, the grouping technique is used to improve the classification accuracy by exposing the group cardinality while reducing both the number of parameters and the training time. The final score is obtained by ensemble of all group classifier outputs using the averaging method. Thirdly, the residual block is improved by including one activation function and one batch normalization layer. Finally, an ensemble-aware loss function is proposed to integrate the independent loss functions of all ensemble members. On the ASVspoof 2019 LA task, the GMM-ResNet2 achieves a minimum t-DCF of 0.0227 and an EER of 0.79\%. On the ASVspoof 2021 LA task, the GMM-ResNet2 achieves a minimum t-DCF of 0.2362 and an EER of 2.19\%, and represents a relative reductions of 31.4\% and 76.3\% compared with the LFCC-LCNN baseline.