 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Visual Safety: Jailbreaking Multimodal Large Language Models for Harmful Image Generation via Semantic-Agnostic Inputs
Jan 22, 2026The rapid advancement of Multimodal Large Language Models (MLLMs) has introduced complex security challenges, particularly at the intersection of textual and visual safety. While existing schemes have explored the security vulnerabilities of MLLMs, the investigation into their visual safety boundaries remains insufficient. In this paper, we propose Beyond Visual Safety (BVS), a novel image-text pair jailbreaking framework specifically designed to probe the visual safety boundaries of MLLMs. BVS employs a "reconstruction-then-generation" strategy, leveraging neutralized visual splicing and inductive recomposition to decouple malicious intent from raw inputs, thereby leading MLLMs to be induced into generating harmful images. Experimental results demonstrate that BVS achieves a remarkable jailbreak success rate of 98.21\% against GPT-5 (12 January 2026 release). Our findings expose critical vulnerabilities in the visual safety alignment of current MLLMs.
Precise Learning of Source Code Contextual Semantics via Hierarchical Dependence Structure and Graph Attention Networks
Nov 20, 2021
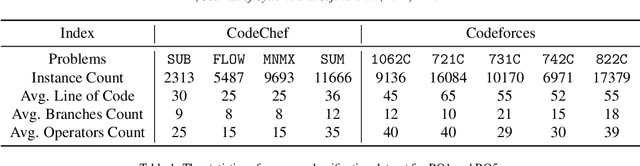
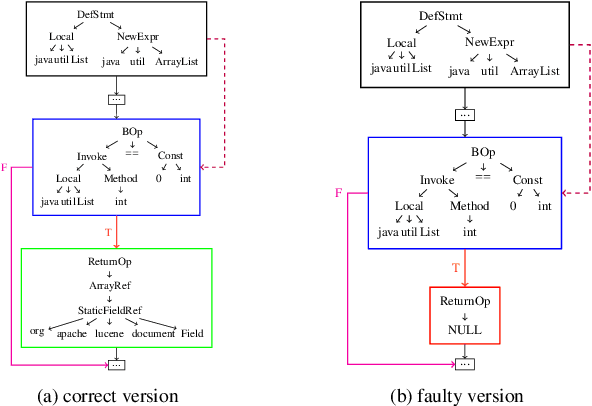
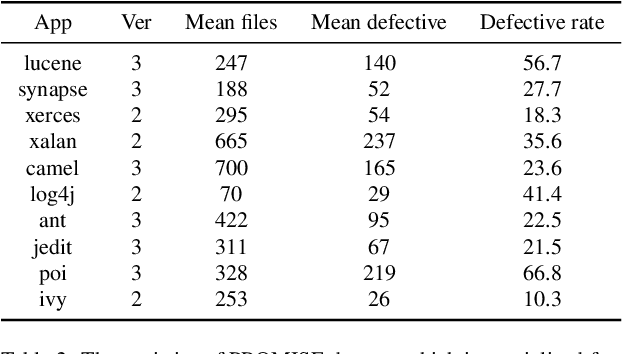
Deep learning is being used extensively in a variety of software engineering tasks, e.g., program classification and defect prediction. Although the technique eliminates the required process of feature engineering, the construction of source code model significantly affects the performance on those tasks. Most recent works was mainly focused on complementing AST-based source code models by introducing contextual dependencies extracted from CFG. However, all of them pay little attention to the representation of basic blocks, which are the basis of contextual dependencies. In this paper, we integrated AST and CFG and proposed a novel source code model embedded with hierarchical dependencies. Based on that, we also designed a neural network that depends on the graph attention mechanism.Specifically, we introduced the syntactic structural of the basic block, i.e., its corresponding AST, in source code model to provide sufficient information and fill the gap. We have evaluated this model on three practical software engineering tasks and compared it with other state-of-the-art methods. The results show that our model can significantly improve the performance. For example, compared to the best performing baseline, our model reduces the scale of parameters by 50\% and achieves 4\% improvement on accuracy on program classification task.
* 17pages, published on Journal of Systems and Software