 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinD-LCE Curve Estimation And Retinex Fusion On Low-Light Image
Jul 19, 2022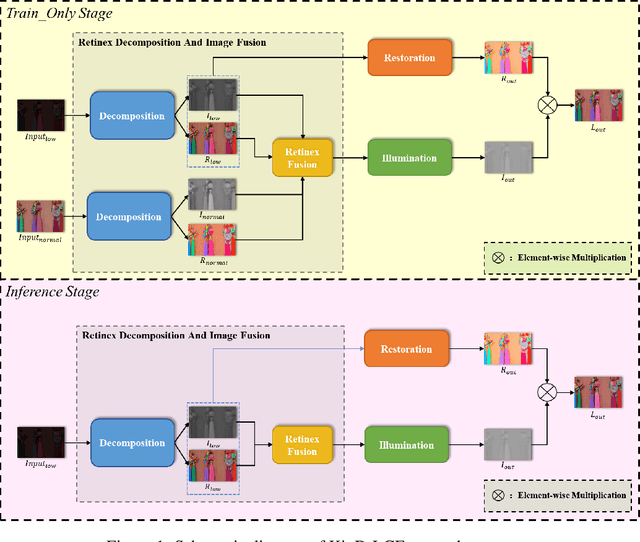

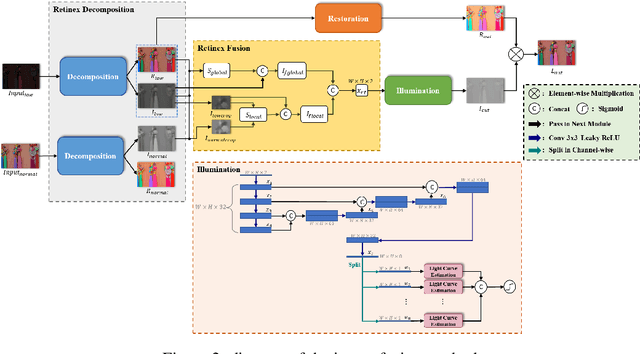

The problems of low light image noise and chromatic aberration is a challenging problem for tasks such as object detection, semantic segmentation, instance segmentation, etc. In this paper, we propose the algorithm for low illumination enhancement. KinD-LCE uses the light curve estimation module in the network structure to enhance the illumination map in the Retinex decomposed image, which improves the image brightness; we proposed the illumination map and reflection map fusion module to restore the restored image details and reduce the detail loss. Finally, we included a total variation loss function to eliminate noise. Our method uses the GladNet dataset as the training set, and the LOL dataset as the test set and is validated using ExDark as the dataset for downstream tasks. Extensive Experiments on the benchmarks demonstrate the advantages of our method and are close to the state-of-the-art results, which achieve a PSNR of 19.7216 and SSIM of 0.8213 in terms of metrics.
Using Frequency Attention to Make Adversarial Patch Powerful Against Person Detector
May 11, 2022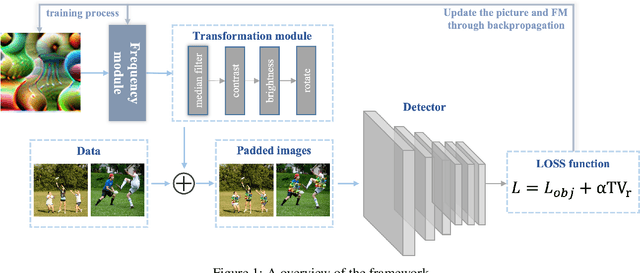

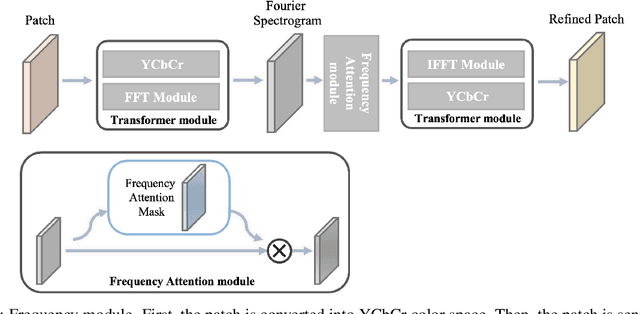
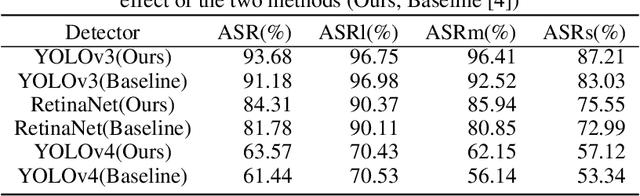
Deep neural networks (DNNs) are vulnerable to adversarial attacks. In particular, object detectors may be attacked by applying a particular adversarial patch to the image. However, because the patch shrinks during preprocessing, most existing approaches that employ adversarial patches to attack object detectors would diminish the attack success rate on small and medium targets. This paper proposes a Frequency Module(FRAN), a frequency-domain attention module for guiding patch generation. This is the first study to introduce frequency domain attention to optimize the attack capabilities of adversarial patches. Our method increases the attack success rates of small and medium targets by 4.18% and 3.89%, respectively, over the state-of-the-art attack method for fooling the human detector while assaulting YOLOv3 without reducing the attack success rate of big targets.
STDC-MA Network for Semantic Segmentation
May 11, 2022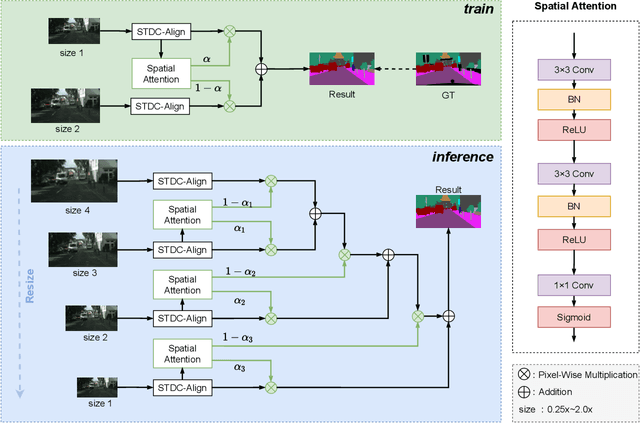

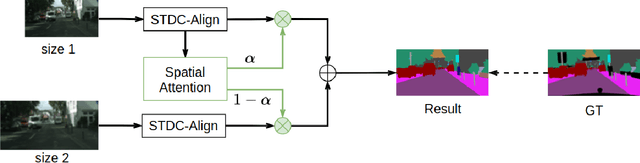
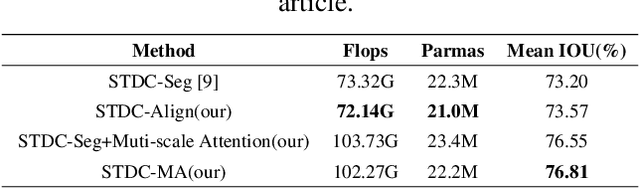
Semantic segmentation is applied extensively in autonomous driving and intelligent transportation with methods that highly demand spatial and semantic information. Here, an STDC-MA network is proposed to meet these demands. First, the STDC-Seg structure is employed in STDC-MA to ensure a lightweight and efficient structure. Subsequently, the feature alignment module (FAM) is applied to understand the offset between high-level and low-level features, solving the problem of pixel offset related to upsampling on the high-level feature map. Our approach implements the effective fusion between high-level features and low-level features. A hierarchical multiscale attention mechanism is adopted to reveal the relationship among attention regions from two different input sizes of one image. Through this relationship, regions receiving much attention are integrated into the segmentation results, thereby reducing the unfocused regions of the input image and improving the effective utilization of multiscale features. STDC- MA maintains the segmentation speed as an STDC-Seg network while improving the segmentation accuracy of small objects. STDC-MA was verified on the verification set of Cityscapes. The segmentation result of STDC-MA attained 76.81% mIOU with the input of 0.5x scale, 3.61% higher than STDC-Seg.