 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDC-MA Network for Semantic Segmentation
Paper and Code
May 11, 2022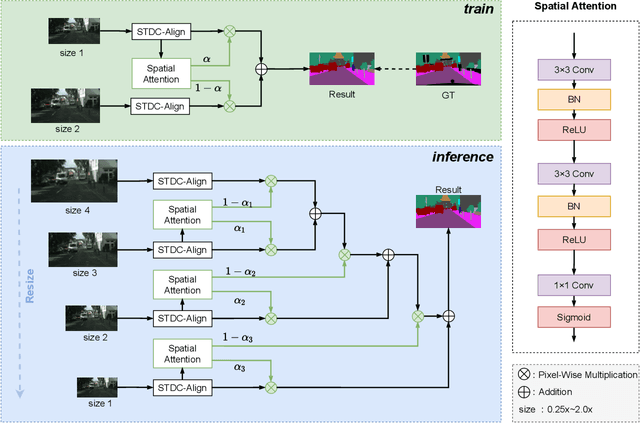

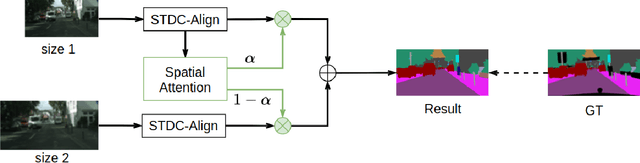
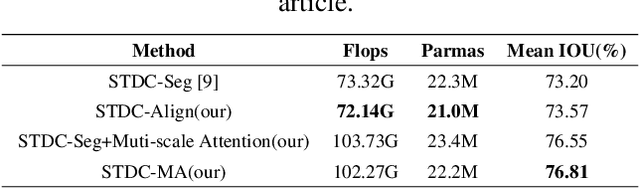
Semantic segmentation is applied extensively in autonomous driving and intelligent transportation with methods that highly demand spatial and semantic information. Here, an STDC-MA network is proposed to meet these demands. First, the STDC-Seg structure is employed in STDC-MA to ensure a lightweight and efficient structure. Subsequently, the feature alignment module (FAM) is applied to understand the offset between high-level and low-level features, solving the problem of pixel offset related to upsampling on the high-level feature map. Our approach implements the effective fusion between high-level features and low-level features. A hierarchical multiscale attention mechanism is adopted to reveal the relationship among attention regions from two different input sizes of one image. Through this relationship, regions receiving much attention are integrated into the segmentation results, thereby reducing the unfocused regions of the input image and improving the effective utilization of multiscale features. STDC- MA maintains the segmentation speed as an STDC-Seg network while improving the segmentation accuracy of small objects. STDC-MA was verified on the verification set of Cityscapes. The segmentation result of STDC-MA attained 76.81% mIOU with the input of 0.5x scale, 3.61% higher than STDC-Seg.