 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAugment: Universal Automatic Data Augmentation Plug-in for Medical Image Analysis
Jun 30, 2023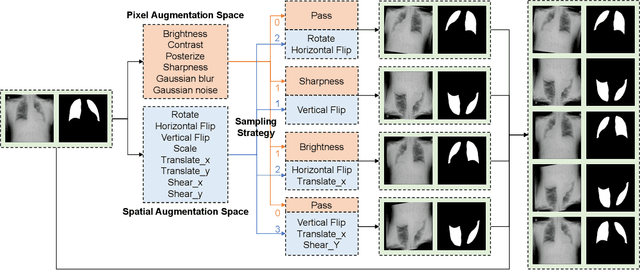
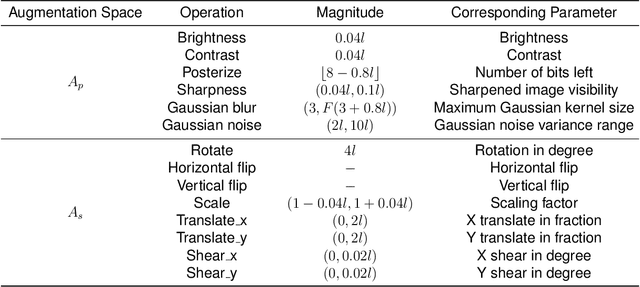
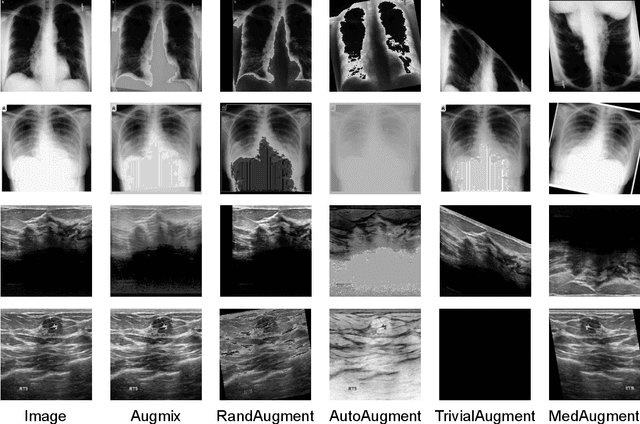
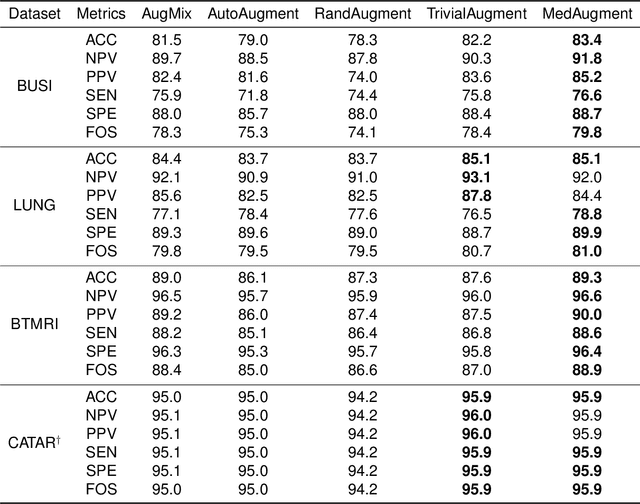
Data Augmentation (DA) technique has been widely implemented in the computer vision field to relieve the data shortage, while the DA in Medical Image Analysis (MIA) is still mostly experience-driven. Here, we develop a plug-and-use DA method, named MedAugment, to introduce the automatic DA argumentation to the MIA field. To settle the difference between natural images and medical images, we divide the augmentation space into pixel augmentation space and spatial augmentation space. A novel operation sampling strategy is also proposed when sampling DA operations from the spaces. To demonstrate the performance and universality of MedAugment, we implement extensive experiments on four classification datasets and three segmentation datasets. The results show that our MedAugment outperforms most state-of-the-art DA methods. This work shows that the plug-and-use MedAugment may benefit the MIA community. Code is available at https://github.com/NUS-Tim/MedAugment_Pytorch.
CECT: Controllable Ensemble CNN and Transformer for COVID-19 image classification by capturing both local and global image features
Feb 05, 2023


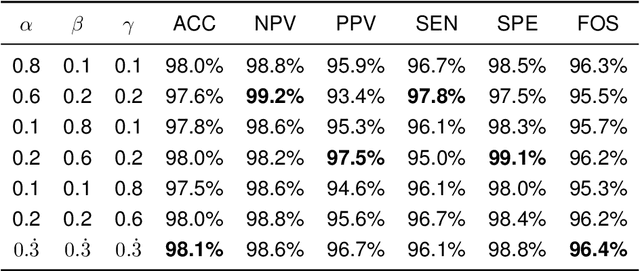
Purpose: Most computer vision models are developed based on either convolutional neural network (CNN) or transformer, while the former (latter) method captures local (global) features. To relieve model performance limitations due to the lack of global (local) features, we develop a novel classification network named CECT by controllable ensemble CNN and transformer. Methods: The proposed CECT is composed of a CNN-based encoder block, a deconvolution-ensemble decoder block, and a transformer-based classification block. Different from conventional CNN- or transformer-based methods, our CECT can capture features at both multi-local and global scales, and the contribution of local features at different scales can be controlled with the proposed ensemble coefficients. Results: We evaluate CECT on two public COVID-19 datasets and it outperforms other state-of-the-art methods on all evaluation metrics. Conclusion: With remarkable feature capture ability, we believe CECT can also be used in other medical image classification scenarios to assist the diagnosis.
Medical image analysis based on transformer: A Review
Aug 13, 2022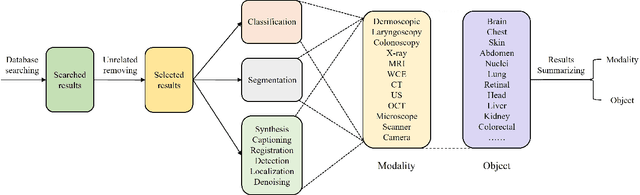

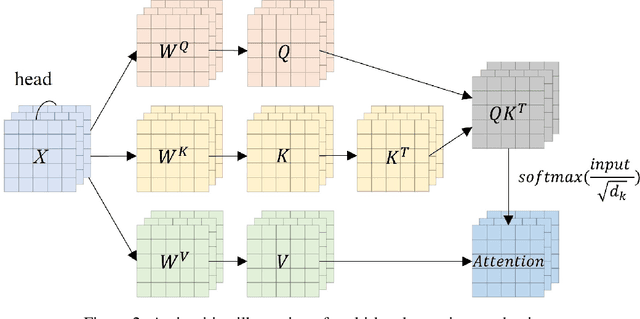
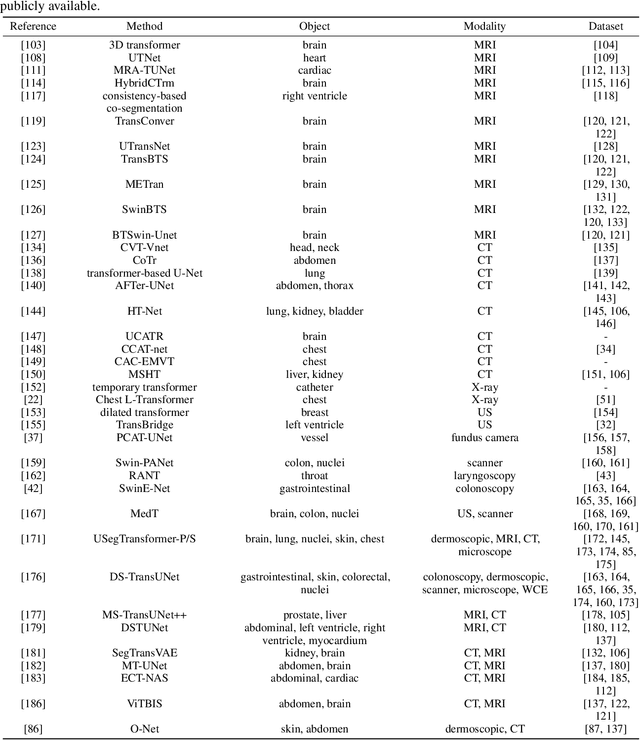
The transformer has dominated the natural language processing (NLP) field for a long time. Recently, the transformer-based method is adopt into the computer vision (CV) field and shows promising results. As an important branch of the CV field, medical image analysis joins the wave of the transformer-based method rightfully. In this paper, we illustrate the principle of the attention mechanism, and the detailed structures of the transformer, and depict how the transformer is adopted into the CV field. We organize the transformer-based medical image analysis applications in the sequence of different CV tasks, including classification, segmentation, synthesis, registration, localization, detection, captioning, and denoising. For the mainstream classification and segmentation tasks, we further divided the corresponding works based on different medical imaging modalities. We include thirteen modalities and more than twenty objects in our work. We also visualize the proportion that each modality and object occupy to give the readers an intuitive impression. We hope our work can contribute to the development of transformer-based medical image analysis in the future.
Semi-supervised classification of medical ultrasound images based on generative adversarial network
Mar 11, 2022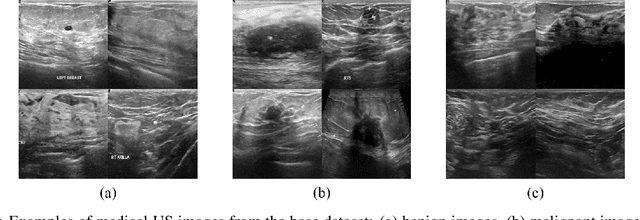
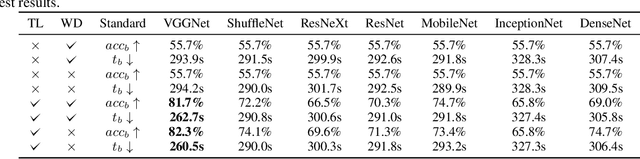
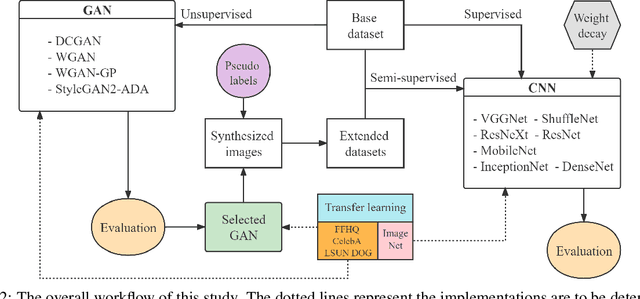

Medical ultrasound (US) is one of the most widely used imaging modalities in clinical practice. However, its use presents unique challenges such as variable imaging quality. Deep learning (DL) can be used as an advanced medical US images analysis tool, while the performance of the DL model is greatly limited by the scarcity of big datasets. Here, we develop semi-supervised classification enhancement (SSCE) structures by constructing seven convolutional neural network (CNN) models and one of the most state-of-the-art generative adversarial network (GAN) models, StyleGAN2-ADA, to address this problem. A breast cancer dataset with 780 images is used as our base dataset. The results show that our SSCE structures obtain an accuracy of up to 97.9%, showing a maximum 21.6% improvement compared with utilizing CNN models alone and outperforming the previous methods using the same dataset by up to 23.9%. We believe our proposed state-of-the-art method can be regarded as a potential auxiliary tool for on-the-fly diagnoses of medical US images.