 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Recurrent Convolutional Neural Network: Improving Performance For Speech Recognition
Dec 27, 2016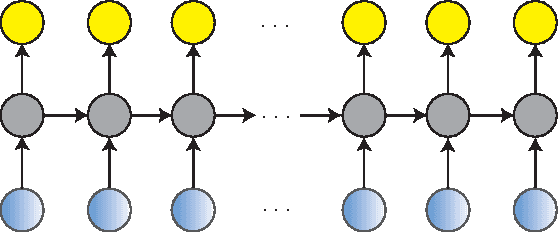
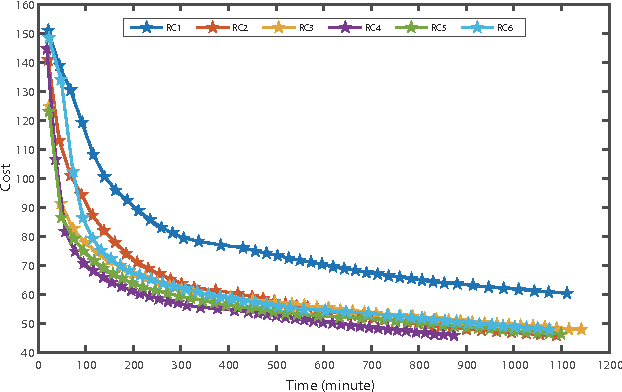
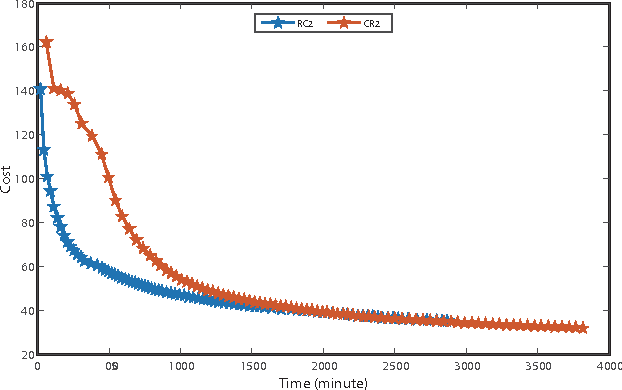
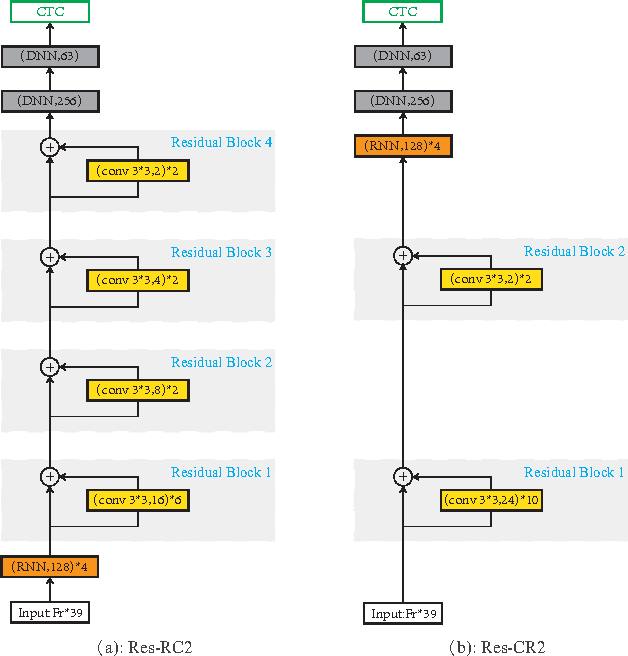
A deep learning approach has been widely applied in sequence modeling problems. In terms of automatic speech recognition (ASR), its performance has significantly been improved by increasing large speech corpus and deeper neural network. Especially, recurrent neural network and deep convolutional neural network have been applied in ASR successfully. Given the arising problem of training speed, we build a novel deep recurrent convolutional network for acoustic modeling and then apply deep residual learning to it. Our experiments show that it has not only faster convergence speed but better recognition accuracy over traditional deep convolutional recurrent network. In the experiments, we compare the convergence speed of our novel deep recurrent convolutional networks and traditional deep convolutional recurrent networks. With faster convergence speed, our novel deep recurrent convolutional networks can reach the comparable performance. We further show that applying deep residual learning can boost the convergence speed of our novel deep recurret convolutional networks. Finally, we evaluate all our experimental networks by phoneme error rate (PER) with our proposed bidirectional statistical n-gram language model. Our evaluation results show that our newly proposed deep recurrent convolutional network applied with deep residual learning can reach the best PER of 17.33\% with the fastest convergence speed on TIMIT database. The outstanding performance of our novel deep recurrent convolutional neural network with deep residual learning indicates that it can be potentially adopted in other sequential problems.
Composing Music with Grammar Argumented Neural Networks and Note-Level Encoding
Dec 07, 2016
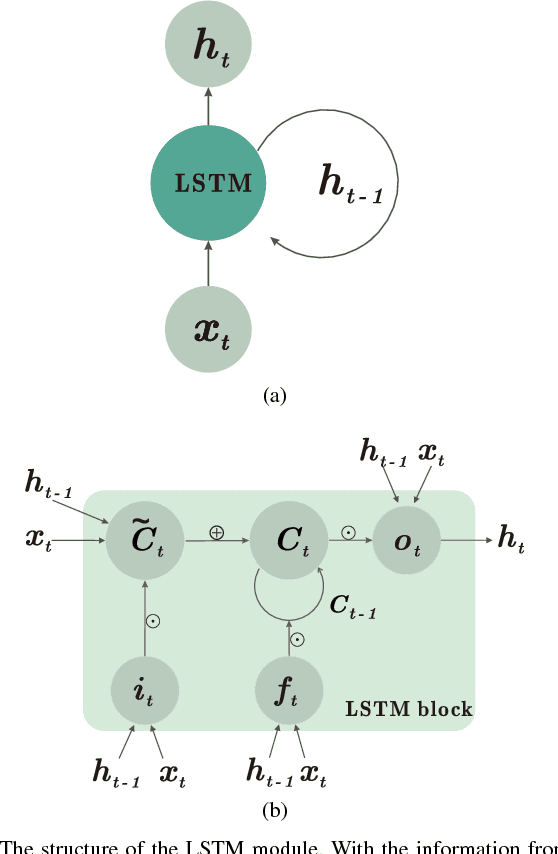
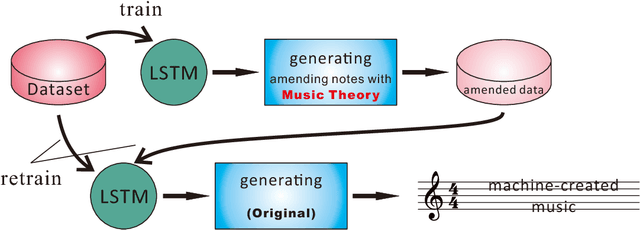

Creating aesthetically pleasing pieces of art, including music, has been a long-term goal for artificial intelligence research. Despite recent successes of long-short term memory (LSTM) recurrent neural networks (RNNs) in sequential learning, LSTM neural networks have not, by themselves, been able to generate natural-sounding music conforming to music theory. To transcend this inadequacy, we put forward a novel method for music composition that combines the LSTM with Grammars motivated by music theory. The main tenets of music theory are encoded as grammar argumented (GA) filters on the training data, such that the machine can be trained to generate music inheriting the naturalness of human-composed pieces from the original dataset while adhering to the rules of music theory. Unlike previous approaches, pitches and durations are encoded as one semantic entity, which we refer to as note-level encoding. This allows easy implementation of music theory grammars, as well as closer emulation of the thinking pattern of a musician. Although the GA rules are applied to the training data and never directly to the LSTM music generation, our machine still composes music that possess high incidences of diatonic scale notes, small pitch intervals and chords, in deference to music theory.