 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-depth Analysis of Passage-Level Label Transfer for Contextual Document Ranking
Mar 30, 2021



Recently introduced pre-trained contextualized autoregressive models like BERT have shown improvements in document retrieval tasks. One of the major limitations of the current approaches can be attributed to the manner they deal with variable-size document lengths using a fixed input BERT model. Common approaches either truncate or split longer documents into small sentences/passages and subsequently label them - using the original document label or from another externally trained model. In this paper, we conduct a detailed study of the design decisions about splitting and label transfer on retrieval effectiveness and efficiency. We find that direct transfer of relevance labels from documents to passages introduces label noise that strongly affects retrieval effectiveness for large training datasets. We also find that query processing times are adversely affected by fine-grained splitting schemes. As a remedy, we propose a careful passage level labelling scheme using weak supervision that delivers improved performance (3-14% in terms of nDCG score) over most of the recently proposed models for ad-hoc retrieval while maintaining manageable computational complexity on four diverse document retrieval datasets.
A study on the Interpretability of Neural Retrieval Models using DeepSHAP
Jul 15, 2019

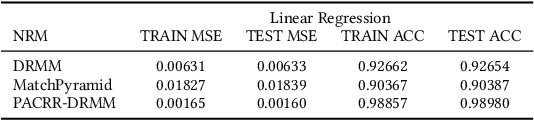
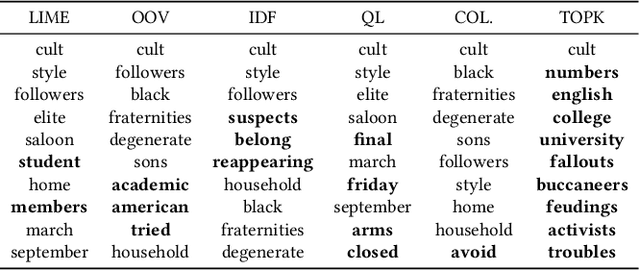
A recent trend in IR has been the usage of neural networks to learn retrieval models for text based adhoc search. While various approaches and architectures have yielded significantly better performance than traditional retrieval models such as BM25, it is still difficult to understand exactly why a document is relevant to a query. In the ML community several approaches for explaining decisions made by deep neural networks have been proposed -- including DeepSHAP which modifies the DeepLift algorithm to estimate the relative importance (shapley values) of input features for a given decision by comparing the activations in the network for a given image against the activations caused by a reference input. In image classification, the reference input tends to be a plain black image. While DeepSHAP has been well studied for image classification tasks, it remains to be seen how we can adapt it to explain the output of Neural Retrieval Models (NRMs). In particular, what is a good "black" image in the context of IR? In this paper we explored various reference input document construction techniques. Additionally, we compared the explanations generated by DeepSHAP to LIME (a model agnostic approach) and found that the explanations differ considerably. Our study raises concerns regarding the robustness and accuracy of explanations produced for NRMs. With this paper we aim to shed light on interesting problems surrounding interpretability in NRMs and highlight areas of future work.