 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Text-to-Image Synthesis with Attention Map Control of Diffusion Models
May 23, 2023



Recent text-to-image (T2I) diffusion models show outstanding performance in generating high-quality images conditioned on textual prompts. However, these models fail to semantically align the generated images with the text descriptions due to their limited compositional capabilities, leading to attribute leakage, entity leakage, and missing entities. In this paper, we propose a novel attention mask control strategy based on predicted object boxes to address these three issues. In particular, we first train a BoxNet to predict a box for each entity that possesses the attribute specified in the prompt. Then, depending on the predicted boxes, unique mask control is applied to the cross- and self-attention maps. Our approach produces a more semantically accurate synthesis by constraining the attention regions of each token in the prompt to the image. In addition, the proposed method is straightforward and effective, and can be readily integrated into existing cross-attention-diffusion-based T2I generators. We compare our approach to competing methods and demonstrate that it not only faithfully conveys the semantics of the original text to the generated content, but also achieves high availability as a ready-to-use plugin.
Unsupervised Multi-Modal Medical Image Registration via Discriminator-Free Image-to-Image Translation
Apr 28, 2022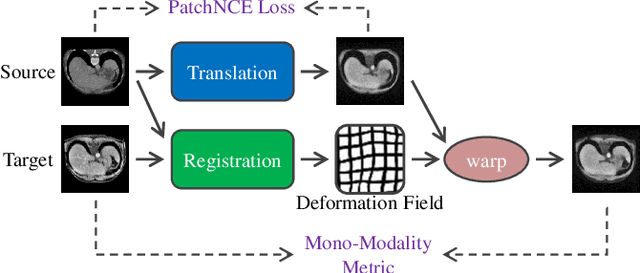
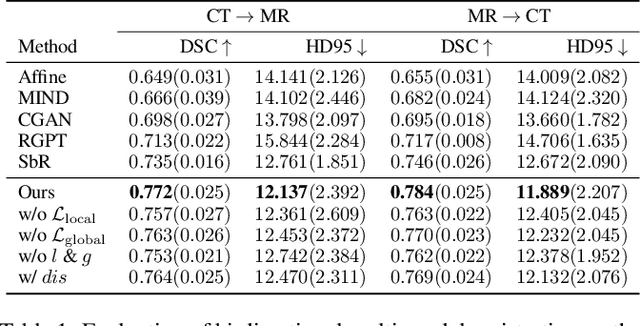
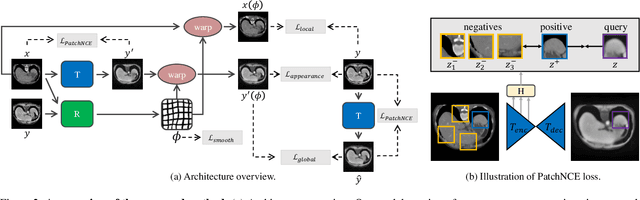
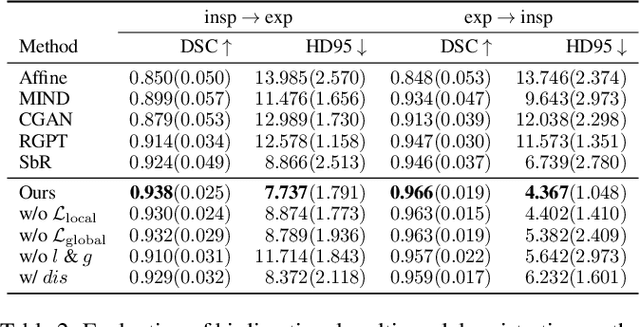
In clinical practice, well-aligned multi-modal images, such as Magnetic Resonance (MR) and Computed Tomography (CT), together can provide complementary information for image-guided therapies. Multi-modal image registration is essential for the accurate alignment of these multi-modal images. However, it remains a very challenging task due to complicated and unknown spatial correspondence between different modalities. In this paper, we propose a novel translation-based unsupervised deformable image registration approach to convert the multi-modal registration problem to a mono-modal one. Specifically, our approach incorporates a discriminator-free translation network to facilitate the training of the registration network and a patchwise contrastive loss to encourage the translation network to preserve object shapes. Furthermore, we propose to replace an adversarial loss, that is widely used in previous multi-modal image registration methods, with a pixel loss in order to integrate the output of translation into the target modality. This leads to an unsupervised method requiring no ground-truth deformation or pairs of aligned images for training. We evaluate four variants of our approach on the public Learn2Reg 2021 datasets \cite{hering2021learn2reg}. The experimental results demonstrate that the proposed architecture achieves state-of-the-art performance. Our code is available at https://github.com/heyblackC/DFMIR.