 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProspectNet: Weighted Conditional Attention for Future Interaction Modeling in Behavior Prediction
Aug 29, 2022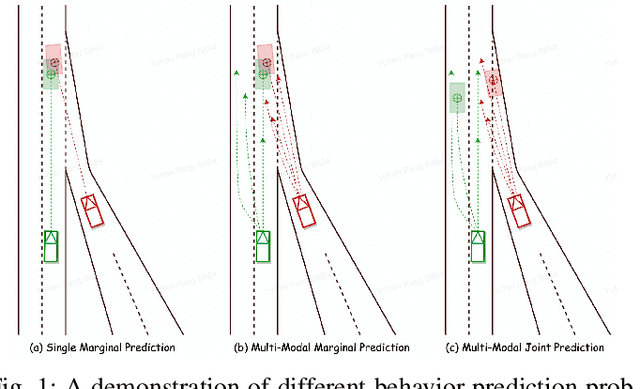


Behavior prediction plays an important role in integrated autonomous driving software solutions. In behavior prediction research, interactive behavior prediction is a less-explored area, compared to single-agent behavior prediction. Predicting the motion of interactive agents requires initiating novel mechanisms to capture the joint behaviors of the interactive pairs. In this work, we formulate the end-to-end joint prediction problem as a sequential learning process of marginal learning and joint learning of vehicle behaviors. We propose ProspectNet, a joint learning block that adopts the weighted attention score to model the mutual influence between interactive agent pairs. The joint learning block first weighs the multi-modal predicted candidate trajectories, then updates the ego-agent's embedding via cross attention. Furthermore, we broadcast the individual future predictions for each interactive agent into a pair-wise scoring module to select the top $K$ prediction pairs. We show that ProspectNet outperforms the Cartesian product of two marginal predictions, and achieves comparable performance on the Waymo Interactive Motion Prediction benchmarks.
CFR-RL: Traffic Engineering with Reinforcement Learning in SDN
Apr 24, 2020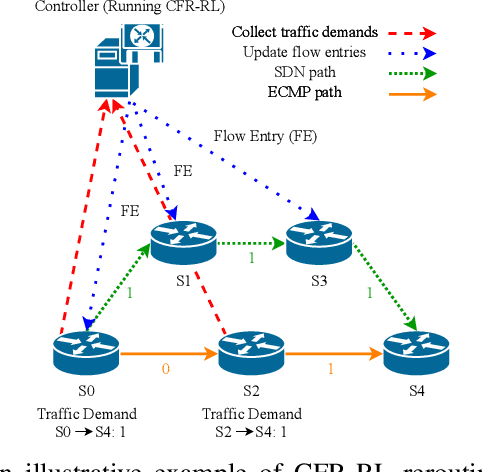
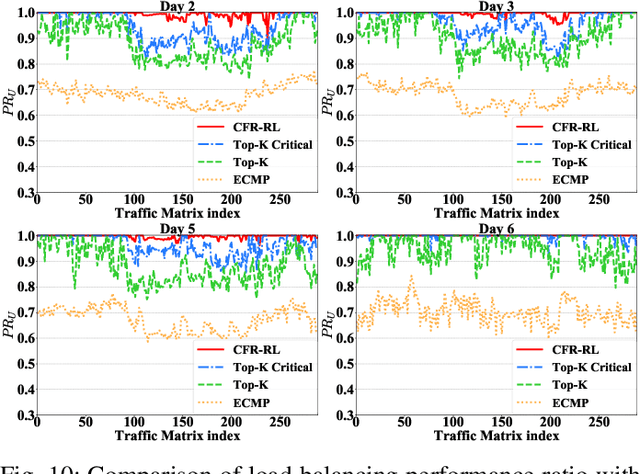
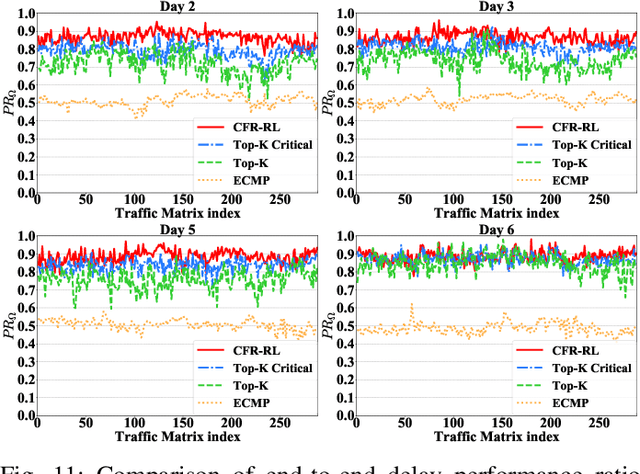
Traditional Traffic Engineering (TE) solutions can achieve the optimal or near-optimal performance by rerouting as many flows as possible. However, they do not usually consider the negative impact, such as packet out of order, when frequently rerouting flows in the network. To mitigate the impact of network disturbance, one promising TE solution is forwarding the majority of traffic flows using Equal-Cost Multi-Path (ECMP) and selectively rerouting a few critical flows using Software-Defined Networking (SDN) to balance link utilization of the network. However, critical flow rerouting is not trivial because the solution space for critical flow selection is enormous. Moreover, it is impossible to design a heuristic algorithm for this problem based on fixed and simple rules, since rule-based heuristics are unable to adapt to the changes of the traffic matrix and network dynamics. In this paper, we propose CFR-RL (Critical Flow Rerouting-Reinforcement Learning), a Reinforcement Learning-based scheme that learns a policy to select critical flows for each given traffic matrix automatically. CFR-RL then reroutes these selected critical flows to balance link utilization of the network by formulating and solving a simple Linear Programming (LP) problem. Extensive evaluations show that CFR-RL achieves near-optimal performance by rerouting only 10%-21.3% of total traffic.