 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Tokenization Strategies for Event Sequence Modeling with Large Language Models
Dec 16, 2025Representing continuous time is a critical and under-explored challenge in modeling temporal event sequences with large language models (LLMs). Various strategies like byte-level representations or calendar tokens have been proposed. However, the optimal approach remains unclear, especially given the diverse statistical distributions of real-world event data, which range from smooth log-normal to discrete, spiky patterns. This paper presents the first empirical study of temporal tokenization for event sequences, comparing distinct encoding strategies: naive numeric strings, high-precision byte-level representations, human-semantic calendar tokens, classic uniform binning, and adaptive residual scalar quantization. We evaluate these strategies by fine-tuning LLMs on real-world datasets that exemplify these diverse distributions. Our analysis reveals that no single strategy is universally superior; instead, prediction performance depends heavily on aligning the tokenizer with the data's statistical properties, with log-based strategies excelling on skewed distributions and human-centric formats proving robust for mixed modalities.
EconWebArena: Benchmarking Autonomous Agents on Economic Tasks in Realistic Web Environments
Jun 09, 2025We introduce EconWebArena, a benchmark for evaluating autonomous agents on complex, multimodal economic tasks in realistic web environments. The benchmark comprises 360 curated tasks from 82 authoritative websites spanning domains such as macroeconomics, labor, finance, trade, and public policy. Each task challenges agents to navigate live websites, interpret structured and visual content, interact with real interfaces, and extract precise, time-sensitive data through multi-step workflows. We construct the benchmark by prompting multiple large language models (LLMs) to generate candidate tasks, followed by rigorous human curation to ensure clarity, feasibility, and source reliability. Unlike prior work, EconWebArena emphasizes fidelity to authoritative data sources and the need for grounded web-based economic reasoning. We evaluate a diverse set of state-of-the-art multimodal LLMs as web agents, analyze failure cases, and conduct ablation studies to assess the impact of visual grounding, plan-based reasoning, and interaction design. Our results reveal substantial performance gaps and highlight persistent challenges in grounding, navigation, and multimodal understanding, positioning EconWebArena as a rigorous testbed for economic web intelligence.
Multi-Agent Collaboration in Incident Response with Large Language Models
Dec 01, 2024Incident response (IR) is a critical aspect of cybersecurity, requiring rapid decision-making and coordinated efforts to address cyberattacks effectively. Leveraging large language models (LLMs) as intelligent agents offers a novel approach to enhancing collaboration and efficiency in IR scenarios. This paper explores the application of LLM-based multi-agent collaboration using the Backdoors & Breaches framework, a tabletop game designed for cybersecurity training. We simulate real-world IR dynamics through various team structures, including centralized, decentralized, and hybrid configurations. By analyzing agent interactions and performance across these setups, we provide insights into optimizing multi-agent collaboration for incident response. Our findings highlight the potential of LLMs to enhance decision-making, improve adaptability, and streamline IR processes, paving the way for more effective and coordinated responses to cyber threats.
Efficient Retrieval of Temporal Event Sequences from Textual Descriptions
Oct 17, 2024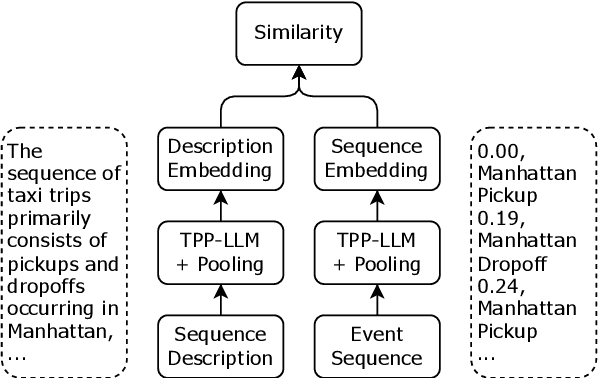
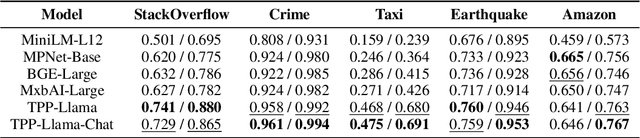
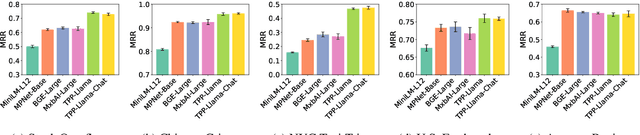
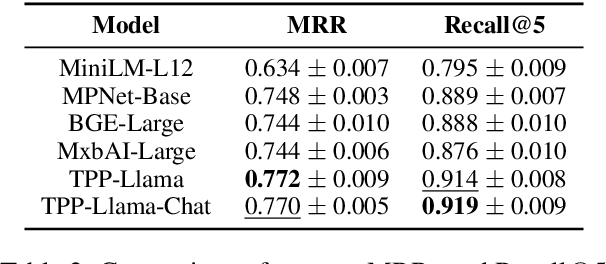
Retrieving temporal event sequences from textual descriptions is essential for applications such as analyzing e-commerce behavior, monitoring social media activities, and tracking criminal incidents. In this paper, we introduce TPP-LLM-Embedding, a unified model for efficiently embedding and retrieving event sequences based on natural language descriptions. Built on the TPP-LLM framework, which integrates large language models with temporal point processes, our model encodes both event types and times, generating a sequence-level representation through pooling. Textual descriptions are embedded using the same architecture, ensuring a shared embedding space for both sequences and descriptions. We optimize a contrastive loss based on similarity between these embeddings, bringing matching pairs closer and separating non-matching ones. TPP-LLM-Embedding enables efficient retrieval and demonstrates superior performance compared to baseline models across diverse datasets.
TPP-LLM: Modeling Temporal Point Processes by Efficiently Fine-Tuning Large Language Models
Oct 02, 2024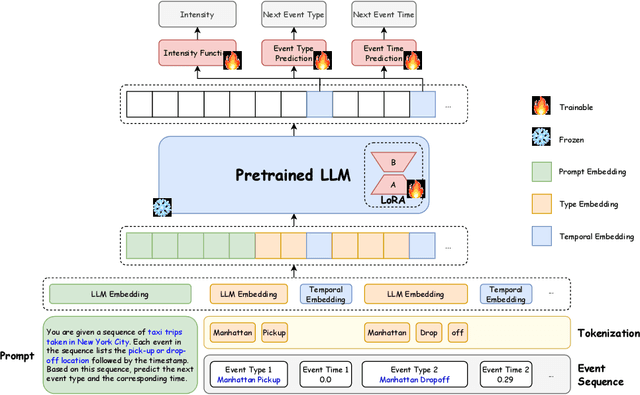
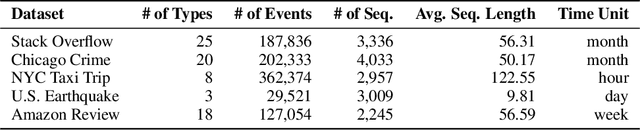
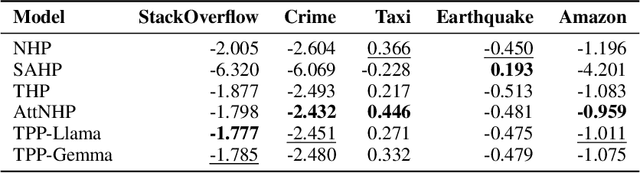
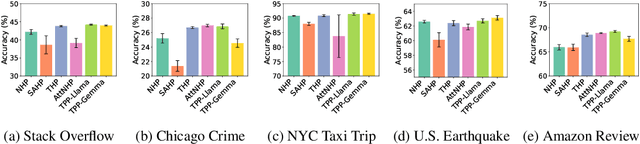
Temporal point processes (TPPs) are widely used to model the timing and occurrence of events in domains such as social networks, transportation systems, and e-commerce. In this paper, we introduce TPP-LLM, a novel framework that integrates large language models (LLMs) with TPPs to capture both the semantic and temporal aspects of event sequences. Unlike traditional methods that rely on categorical event type representations, TPP-LLM directly utilizes the textual descriptions of event types, enabling the model to capture rich semantic information embedded in the text. While LLMs excel at understanding event semantics, they are less adept at capturing temporal patterns. To address this, TPP-LLM incorporates temporal embeddings and employs parameter-efficient fine-tuning (PEFT) methods to effectively learn temporal dynamics without extensive retraining. This approach improves both predictive accuracy and computational efficiency. Experimental results across diverse real-world datasets demonstrate that TPP-LLM outperforms state-of-the-art baselines in sequence modeling and event prediction, highlighting the benefits of combining LLMs with TPPs.
InvAgent: A Large Language Model based Multi-Agent System for Inventory Management in Supply Chains
Jul 16, 2024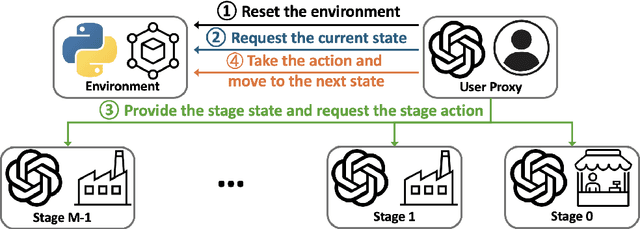

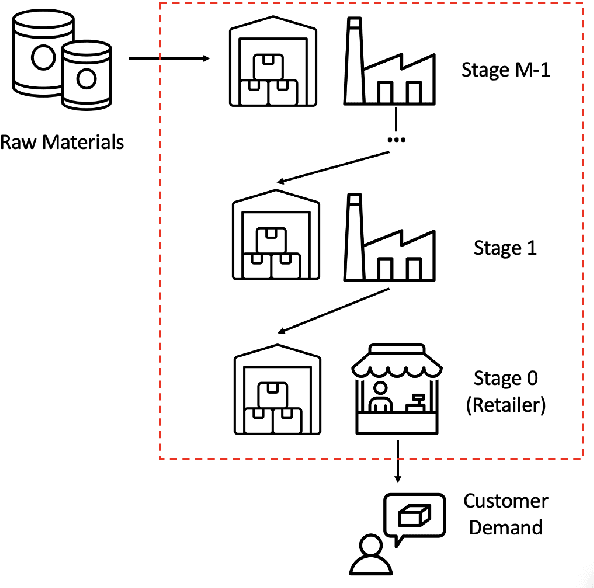
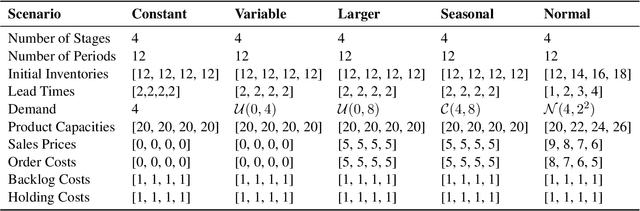
Supply chain management (SCM) involves coordinating the flow of goods, information, and finances across various entities to deliver products efficiently. Effective inventory management is crucial in today's volatile, uncertain, complex, and ambiguous (VUCA) world. Previous research has demonstrated the superiority of heuristic methods and reinforcement learning applications in inventory management. However, the application of large language models (LLMs) as autonomous agents in multi-agent systems for inventory management remains underexplored. This study introduces a novel approach using LLMs to manage multi-agent inventory systems. Leveraging their zero-shot learning capabilities, our model, InvAgent, enhances resilience and improves efficiency across the supply chain network. Our contributions include utilizing LLMs for zero-shot learning to enable adaptive and informed decision-making without prior training, providing significant explainability and clarity through Chain-of-Thought (CoT), and demonstrating dynamic adaptability to varying demand scenarios while minimizing costs and avoiding stockouts. Extensive evaluations across different scenarios highlight the efficiency of our model in SCM.
EconLogicQA: A Question-Answering Benchmark for Evaluating Large Language Models in Economic Sequential Reasoning
May 13, 2024In this paper, we introduce EconLogicQA, a rigorous benchmark designed to assess the sequential reasoning capabilities of large language models (LLMs) within the intricate realms of economics, business, and supply chain management. Diverging from traditional benchmarks that predict subsequent events individually, EconLogicQA poses a more challenging task: it requires models to discern and sequence multiple interconnected events, capturing the complexity of economic logics. EconLogicQA comprises an array of multi-event scenarios derived from economic articles, which necessitate an insightful understanding of both temporal and logical event relationships. Through comprehensive evaluations, we exhibit that EconLogicQA effectively gauges a LLM's proficiency in navigating the sequential complexities inherent in economic contexts. We provide a detailed description of EconLogicQA dataset and shows the outcomes from evaluating the benchmark across various leading-edge LLMs, thereby offering a thorough perspective on their sequential reasoning potential in economic contexts. Our benchmark dataset is available at https://huggingface.co/datasets/yinzhu-quan/econ_logic_qa.
AdaMoLE: Fine-Tuning Large Language Models with Adaptive Mixture of Low-Rank Adaptation Experts
May 01, 2024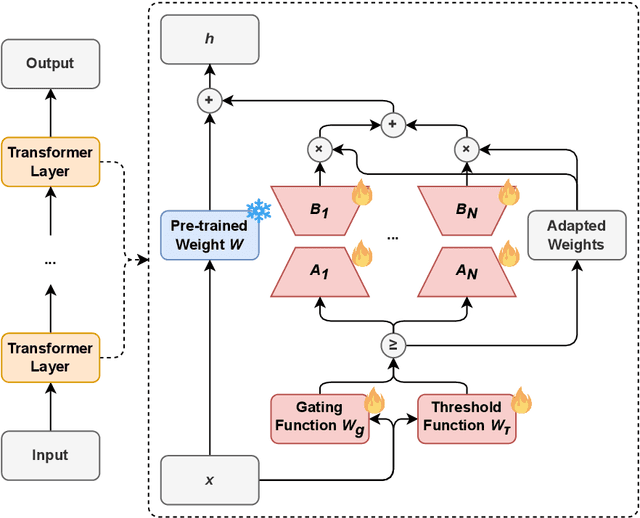

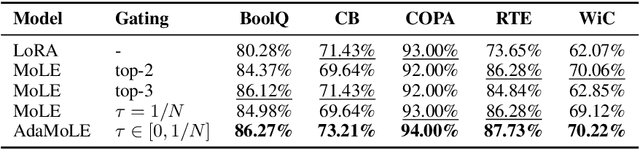
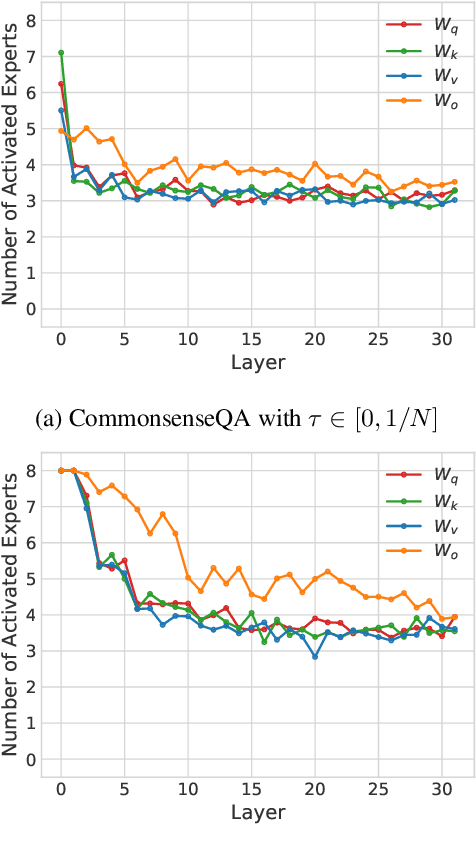
We introduce AdaMoLE, a novel method for fine-tuning large language models (LLMs) through an Adaptive Mixture of Low-Rank Adaptation (LoRA) Experts. Moving beyond conventional methods that employ a static top-k strategy for activating experts, AdaMoLE dynamically adjusts the activation threshold using a dedicated threshold network, adaptively responding to the varying complexities of different tasks. By replacing a single LoRA in a layer with multiple LoRA experts and integrating a gating function with the threshold mechanism, AdaMoLE effectively selects and activates the most appropriate experts based on the input context. Our extensive evaluations across a variety of commonsense reasoning and natural language processing tasks show that AdaMoLE exceeds baseline performance. This enhancement highlights the advantages of AdaMoLE's adaptive selection of LoRA experts, improving model effectiveness without a corresponding increase in the expert count. The experimental validation not only confirms AdaMoLE as a robust approach for enhancing LLMs but also suggests valuable directions for future research in adaptive expert selection mechanisms, potentially broadening the scope for optimizing model performance across diverse language processing tasks.
Application of Neural Ordinary Differential Equations for Tokamak Plasma Dynamics Analysis
Mar 03, 2024In the quest for controlled thermonuclear fusion, tokamaks present complex challenges in understanding burning plasma dynamics. This study introduces a multi-region multi-timescale transport model, employing Neural Ordinary Differential Equations (Neural ODEs) to simulate the intricate energy transfer processes within tokamaks. Our methodology leverages Neural ODEs for the numerical derivation of diffusivity parameters from DIII-D tokamak experimental data, enabling the precise modeling of energy interactions between electrons and ions across various regions, including the core, edge, and scrape-off layer. These regions are conceptualized as distinct nodes, capturing the critical timescales of radiation and transport processes essential for efficient tokamak operation. Validation against DIII-D plasmas under various auxiliary heating conditions demonstrates the model's effectiveness, ultimately shedding light on ways to enhance tokamak performance with deep learning.
SecQA: A Concise Question-Answering Dataset for Evaluating Large Language Models in Computer Security
Dec 26, 2023In this paper, we introduce SecQA, a novel dataset tailored for evaluating the performance of Large Language Models (LLMs) in the domain of computer security. Utilizing multiple-choice questions generated by GPT-4 based on the "Computer Systems Security: Planning for Success" textbook, SecQA aims to assess LLMs' understanding and application of security principles. We detail the structure and intent of SecQA, which includes two versions of increasing complexity, to provide a concise evaluation across various difficulty levels. Additionally, we present an extensive evaluation of prominent LLMs, including GPT-3.5-Turbo, GPT-4, Llama-2, Vicuna, Mistral, and Zephyr models, using both 0-shot and 5-shot learning settings. Our results, encapsulated in the SecQA v1 and v2 datasets, highlight the varying capabilities and limitations of these models in the computer security context. This study not only offers insights into the current state of LLMs in understanding security-related content but also establishes SecQA as a benchmark for future advancements in this critical research area.