 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Retrieval of Temporal Event Sequences from Textual Descriptions
Paper and Code
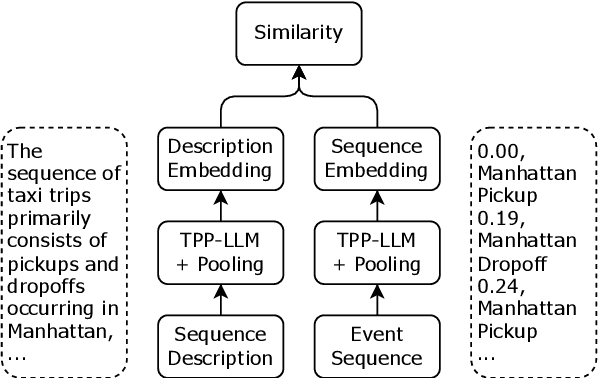
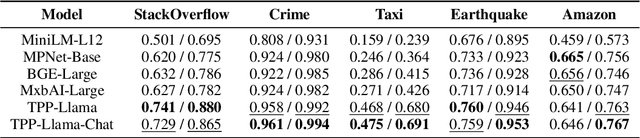
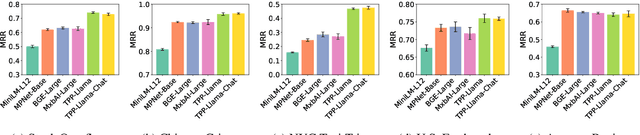
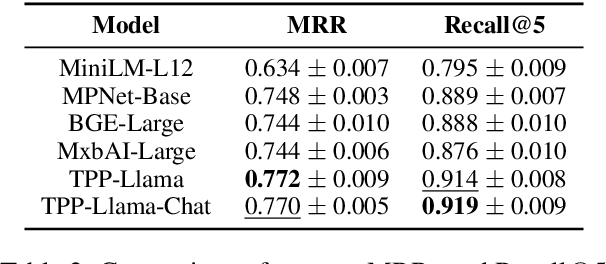
Retrieving temporal event sequences from textual descriptions is essential for applications such as analyzing e-commerce behavior, monitoring social media activities, and tracking criminal incidents. In this paper, we introduce TPP-LLM-Embedding, a unified model for efficiently embedding and retrieving event sequences based on natural language descriptions. Built on the TPP-LLM framework, which integrates large language models with temporal point processes, our model encodes both event types and times, generating a sequence-level representation through pooling. Textual descriptions are embedded using the same architecture, ensuring a shared embedding space for both sequences and descriptions. We optimize a contrastive loss based on similarity between these embeddings, bringing matching pairs closer and separating non-matching ones. TPP-LLM-Embedding enables efficient retrieval and demonstrates superior performance compared to baseline models across diverse datasets.