 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Expert Quantization for Scalable Mixture-of-Experts Inference
Nov 19, 2025Mixture-of-Experts (MoE) models scale LLM capacity efficiently, but deployment on consumer GPUs is limited by the large memory footprint of inactive experts. Static post-training quantization reduces storage costs but cannot adapt to shifting activation patterns, causing accuracy loss under aggressive compression. So we present DynaExq, a runtime system that treats expert precision as a first-class, dynamically managed resource. DynaExq combines (1) a hotness-aware precision controller that continuously aligns expert bit-widths with long-term activation statistics, (2) a fully asynchronous precision-switching pipeline that overlaps promotion and demotion with MoE computation, and (3) a fragmentation-free memory pooling mechanism that supports hybrid-precision experts with deterministic allocation. Together, these components enable stable, non-blocking precision transitions under strict HBM budgets. Across Qwen3-30B and Qwen3-80B MoE models and six representative benchmarks, DynaExq deploys large LLMs on single RTX 5090 and A6000 GPUs and improves accuracy by up to 4.03 points over static low-precision baselines. The results show that adaptive, workload-aware quantization is an effective strategy for memory-constrained MoE serving.
Learning Multi-Modal Brain Tumor Segmentation from Privileged Semi-Paired MRI Images with Curriculum Disentanglement Learning
Aug 26, 2022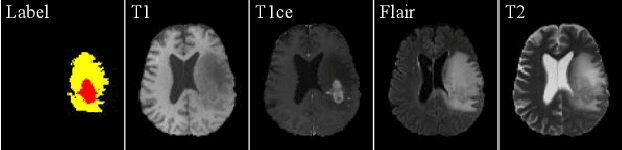
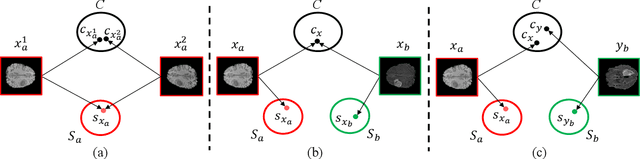
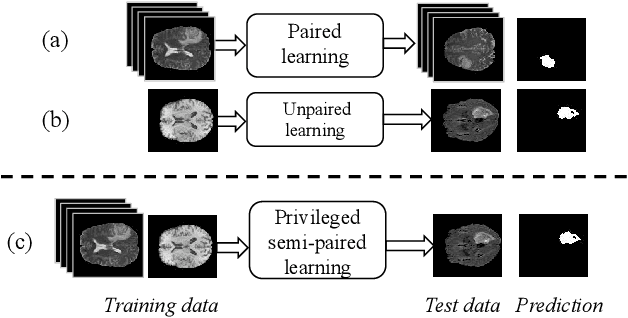
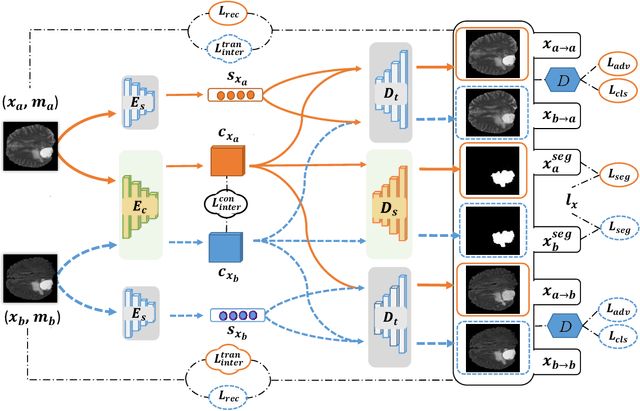
Due to the difficulties of obtaining multimodal paired images in clinical practice, recent studies propose to train brain tumor segmentation models with unpaired images and capture complementary information through modality translation. However, these models cannot fully exploit the complementary information from different modalities. In this work, we thus present a novel two-step (intra-modality and inter-modality) curriculum disentanglement learning framework to effectively utilize privileged semi-paired images, i.e. limited paired images that are only available in training, for brain tumor segmentation. Specifically, in the first step, we propose to conduct reconstruction and segmentation with augmented intra-modality style-consistent images. In the second step, the model jointly performs reconstruction, unsupervised/supervised translation, and segmentation for both unpaired and paired inter-modality images. A content consistency loss and a supervised translation loss are proposed to leverage complementary information from different modalities in this step. Through these two steps, our method effectively extracts modality-specific style codes describing the attenuation of tissue features and image contrast, and modality-invariant content codes containing anatomical and functional information from the input images. Experiments on three brain tumor segmentation tasks show that our model outperforms competing segmentation models based on unpaired images.
TFusion: Transformer based N-to-One Multimodal Fusion Block
Aug 26, 2022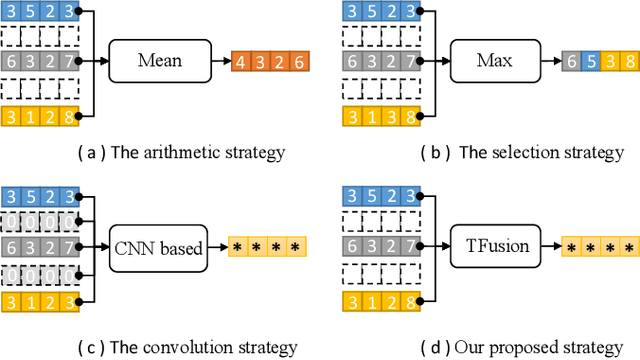
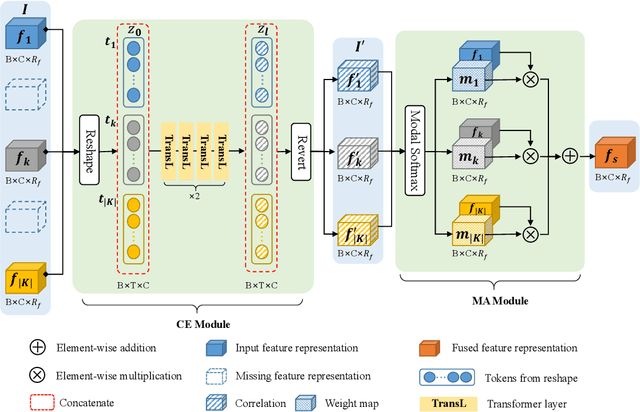
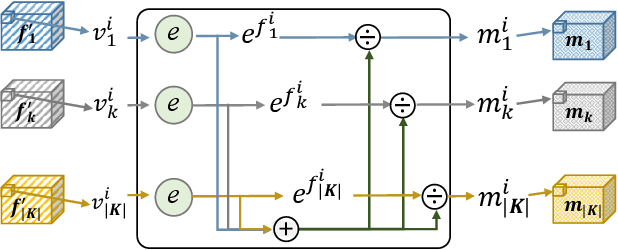
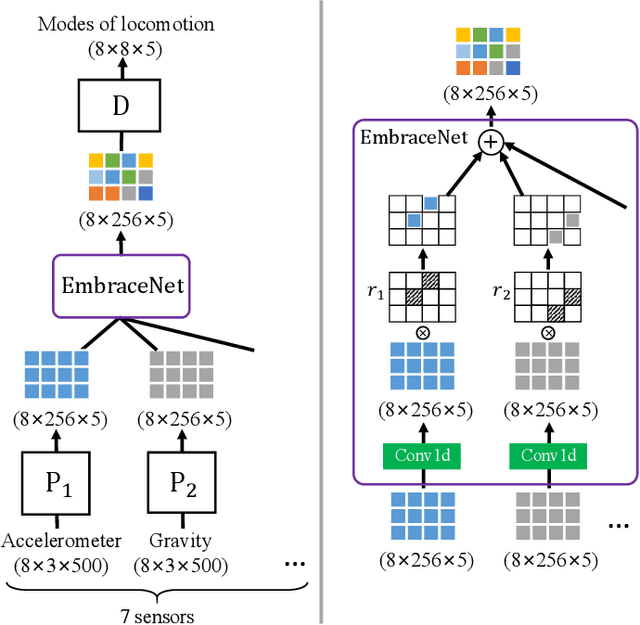
People perceive the world with different senses, such as sight, hearing, smell, and touch. Processing and fusing information from multiple modalities enables Artificial Intelligence to understand the world around us more easily. However, when there are missing modalities, the number of available modalities is different in diverse situations, which leads to an N-to-One fusion problem. To solve this problem, we propose a transformer based fusion block called TFusion. Different from preset formulations or convolution based methods, the proposed block automatically learns to fuse available modalities without synthesizing or zero-padding missing ones. Specifically, the feature representations extracted from upstream processing model are projected as tokens and fed into transformer layers to generate latent multimodal correlations. Then, to reduce the dependence on particular modalities, a modal attention mechanism is introduced to build a shared representation, which can be applied by the downstream decision model. The proposed TFusion block can be easily integrated into existing multimodal analysis networks. In this work, we apply TFusion to different backbone networks for multimodal human activity recognition and brain tumor segmentation tasks. Extensive experimental results show that the TFusion block achieves better performance than the competing fusion strategies.