 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Modal Brain Tumor Segmentation from Privileged Semi-Paired MRI Images with Curriculum Disentanglement Learning
Paper and Code
Aug 26, 2022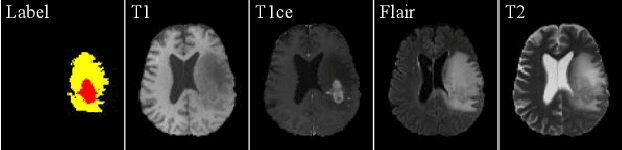
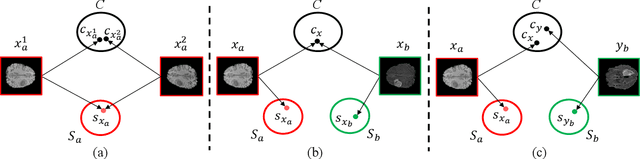
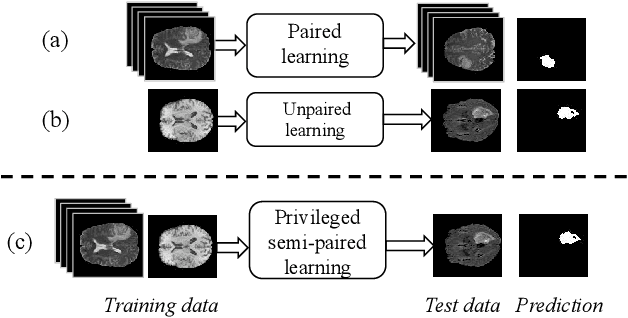
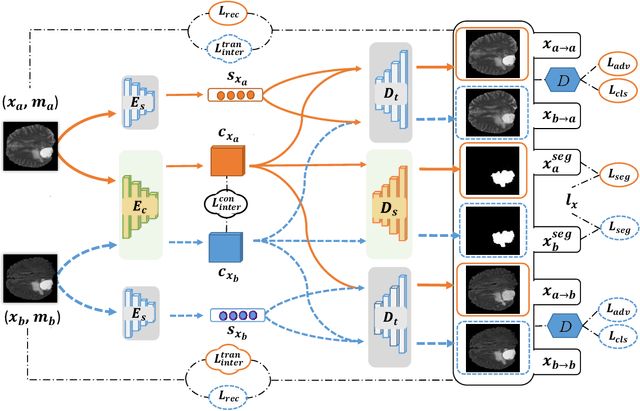
Due to the difficulties of obtaining multimodal paired images in clinical practice, recent studies propose to train brain tumor segmentation models with unpaired images and capture complementary information through modality translation. However, these models cannot fully exploit the complementary information from different modalities. In this work, we thus present a novel two-step (intra-modality and inter-modality) curriculum disentanglement learning framework to effectively utilize privileged semi-paired images, i.e. limited paired images that are only available in training, for brain tumor segmentation. Specifically, in the first step, we propose to conduct reconstruction and segmentation with augmented intra-modality style-consistent images. In the second step, the model jointly performs reconstruction, unsupervised/supervised translation, and segmentation for both unpaired and paired inter-modality images. A content consistency loss and a supervised translation loss are proposed to leverage complementary information from different modalities in this step. Through these two steps, our method effectively extracts modality-specific style codes describing the attenuation of tissue features and image contrast, and modality-invariant content codes containing anatomical and functional information from the input images. Experiments on three brain tumor segmentation tasks show that our model outperforms competing segmentation models based on unpaired images.