 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFusion: Transformer based N-to-One Multimodal Fusion Block
Paper and Code
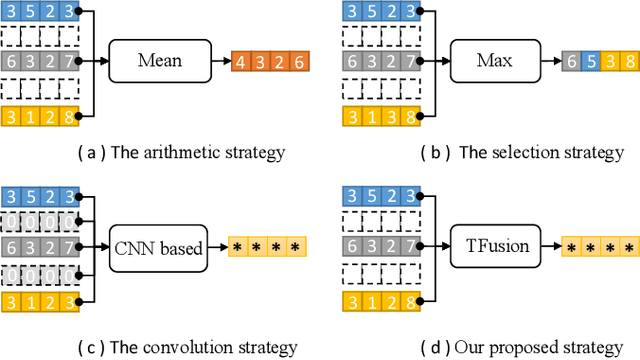
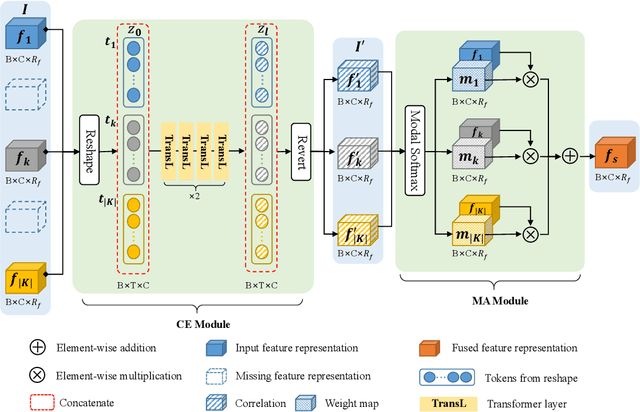
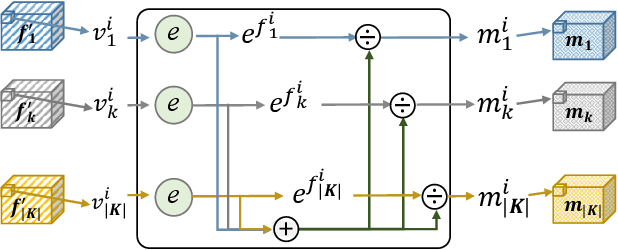
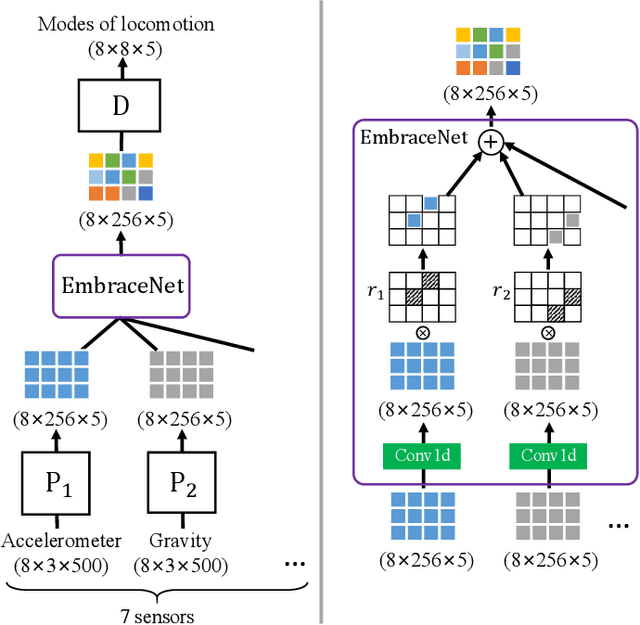
People perceive the world with different senses, such as sight, hearing, smell, and touch. Processing and fusing information from multiple modalities enables Artificial Intelligence to understand the world around us more easily. However, when there are missing modalities, the number of available modalities is different in diverse situations, which leads to an N-to-One fusion problem. To solve this problem, we propose a transformer based fusion block called TFusion. Different from preset formulations or convolution based methods, the proposed block automatically learns to fuse available modalities without synthesizing or zero-padding missing ones. Specifically, the feature representations extracted from upstream processing model are projected as tokens and fed into transformer layers to generate latent multimodal correlations. Then, to reduce the dependence on particular modalities, a modal attention mechanism is introduced to build a shared representation, which can be applied by the downstream decision model. The proposed TFusion block can be easily integrated into existing multimodal analysis networks. In this work, we apply TFusion to different backbone networks for multimodal human activity recognition and brain tumor segmentation tasks. Extensive experimental results show that the TFusion block achieves better performance than the competing fusion strategies.