 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Recurrent Neural Networks Optimization for the Edge -- a Quantization-based Approach
Aug 02, 2021
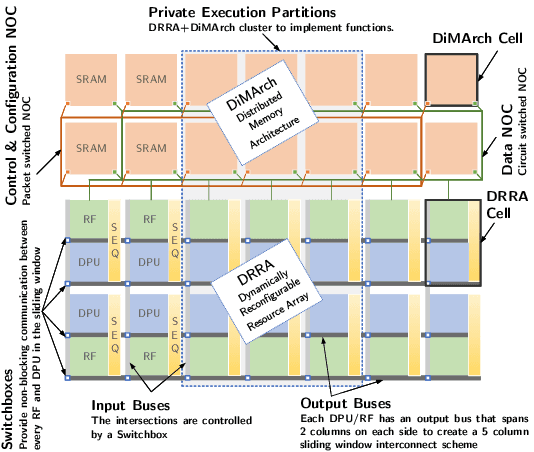

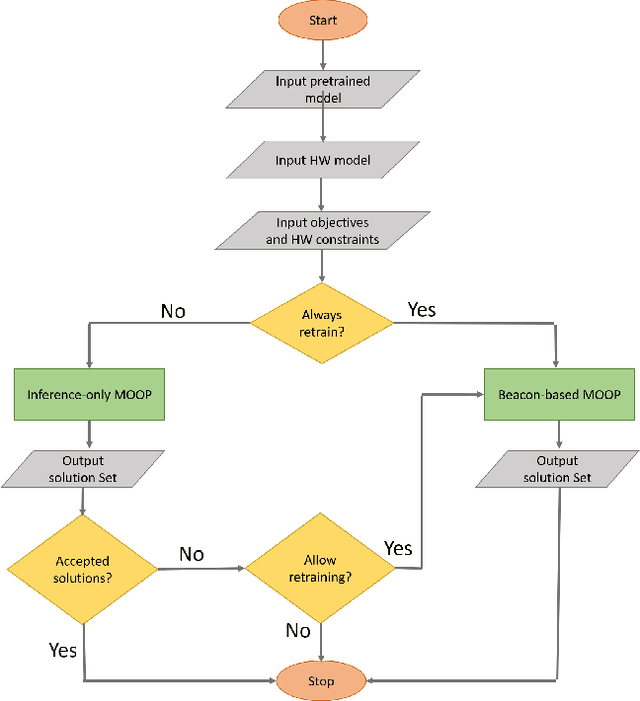
The compression of deep learning models is of fundamental importance in deploying such models to edge devices. Incorporating hardware model and application constraints during compression maximizes the benefits but makes it specifically designed for one case. Therefore, the compression needs to be automated. Searching for the optimal compression method parameters is considered an optimization problem. This article introduces a Multi-Objective Hardware-Aware Quantization (MOHAQ) method, which considers both hardware efficiency and inference error as objectives for mixed-precision quantization. The proposed method makes the evaluation of candidate solutions in a large search space feasible by relying on two steps. First, post-training quantization is applied for fast solution evaluation. Second, we propose a search technique named "beacon-based search" to retrain selected solutions only in the search space and use them as beacons to know the effect of retraining on other solutions. To evaluate the optimization potential, we chose a speech recognition model using the TIMIT dataset. The model is based on Simple Recurrent Unit (SRU) due to its considerable speedup over other recurrent units. We applied our method to run on two platforms: SiLago and Bitfusion. Experimental evaluations showed that SRU can be compressed up to 8x by post-training quantization without any significant increase in the error and up to 12x with only a 1.5 percentage point increase in error. On SiLago, the inference-only search found solutions that achieve 80\% and 64\% of the maximum possible speedup and energy saving, respectively, with a 0.5 percentage point increase in the error. On Bitfusion, with a constraint of a small SRAM size, beacon-based search reduced the error gain of inference-only search by 4 percentage points and increased the possible reached speedup to be 47x compared to the Bitfusion baseline.
Recurrent Neural Networks: An Embedded Computing Perspective
Jul 23, 2019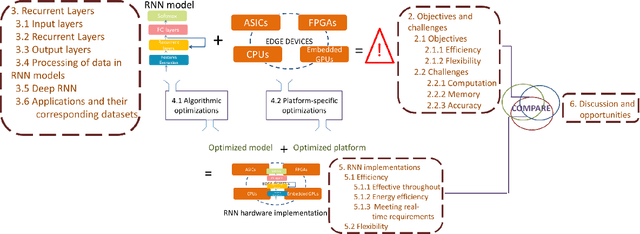
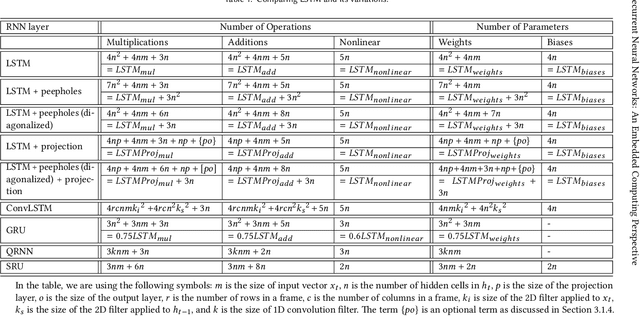
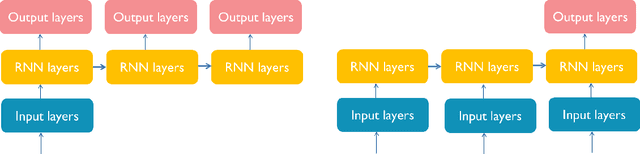
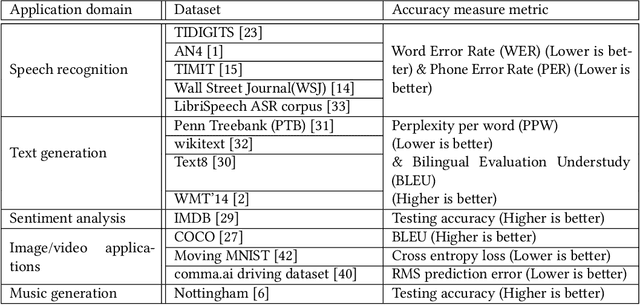
Recurrent Neural Networks (RNNs) are a class of machine learning algorithms used for applications with time-series and sequential data. Recently, a strong interest has emerged to execute RNNs on embedded devices. However, RNN requirements of high computational capability and large memory space is difficult to be met. In this paper, we review the existing implementations of RNN models on embedded platforms and discuss the methods adopted to overcome the limitations of embedded systems. We define the objectives of mapping RNN algorithms on embedded platforms and the challenges facing their realization. Then, we explain the components of RNNs models from an implementation perspective. Furthermore, we discuss the optimizations applied on RNNs to run efficiently on embedded platforms. Additionally, we compare the defined objectives with the implementations and highlight some open research questions and aspects currently not addressed for embedded RNNs. The paper concludes that applying algorithmic optimizations on RNN models is vital while designing an embedded solution. In addition, using the on-chip memory to store the weights or having an efficient compute-load overlap is essential to overcome the high memory access overhead. Nevertheless, the survey concludes that high performance has been targeted by many implementations while flexibility was still less attempted.