 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinearization Explains Fine-Tuning in Large Language Models
Feb 09, 2026Parameter-Efficient Fine-Tuning (PEFT) is a popular class of techniques that strive to adapt large models in a scalable and resource-efficient manner. Yet, the mechanisms underlying their training performance and generalization remain underexplored. In this paper, we provide several insights into such fine-tuning through the lens of linearization. Fine-tuned models are often implicitly encouraged to remain close to the pretrained model. By making this explicit, using an Euclidean distance inductive bias in parameter space, we show that fine-tuning dynamics become equivalent to learning with the positive-definite neural tangent kernel (NTK). We specifically analyze how close the fully linear and the linearized fine-tuning optimizations are, based on the strength of the regularization. This allows us to be pragmatic about how good a model linearization is when fine-tuning large language models (LLMs). When linearization is a good model, our findings reveal a strong correlation between the eigenvalue spectrum of the NTK and the performance of model adaptation. Motivated by this, we give spectral perturbation bounds on the NTK induced by the choice of layers selected for fine-tuning. We empirically validate our theory on Low Rank Adaptation (LoRA) on LLMs. These insights not only characterize fine-tuning but also have the potential to enhance PEFT techniques, paving the way to better informed and more nimble adaptation in LLMs.
Optimal tool path planning for 3D printing with spatio-temporal and thermal constraints
Jul 19, 2020
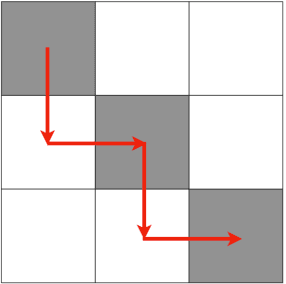
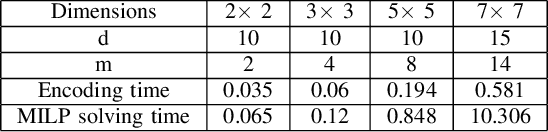
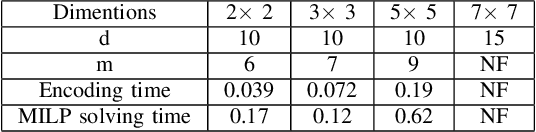
In this paper, we address the problem of synthesizing optimal path plans in a 2D subject to spatio-temporal and thermal constraints. Our solution consists of reducing the path planning problem to a Mixed Integer Linear Programming (MILP) problem. The challenge is in encoding the implication constraints in the path planning problem using only conjunctions that are permitted by the MILP formulation. Our experimental analysis using an implementation of the encoding in a Python toolbox demonstrates the feasibility of our approach in generating the optimal plans.
Abstraction based Output Range Analysis for Neural Networks
Jul 18, 2020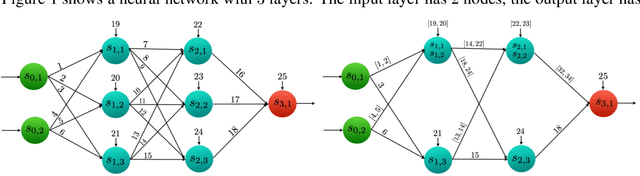
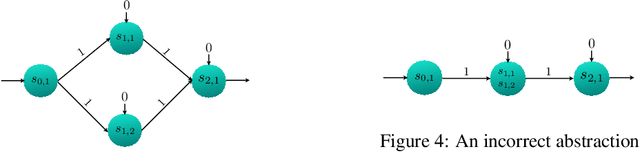

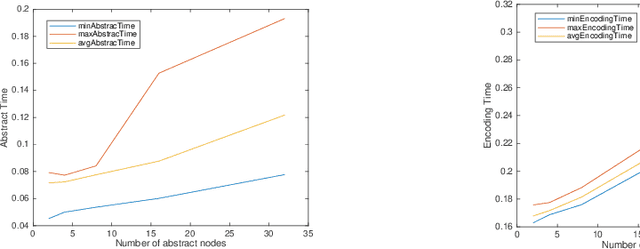
In this paper, we consider the problem of output range analysis for feed-forward neural networks with ReLU activation functions. The existing approaches reduce the output range analysis problem to satisfiability and optimization solving, which are NP-hard problems, and whose computational complexity increases with the number of neurons in the network. To tackle the computational complexity, we present a novel abstraction technique that constructs a simpler neural network with fewer neurons, albeit with interval weights called interval neural network (INN), which over-approximates the output range of the given neural network. We reduce the output range analysis on the INNs to solving a mixed integer linear programming problem. Our experimental results highlight the trade-off between the computation time and the precision of the computed output range.