 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fusion of Labeled-Grid Shape Descriptors with Weighted Ranking Algorithm for Shapes Recognition
Jun 16, 2014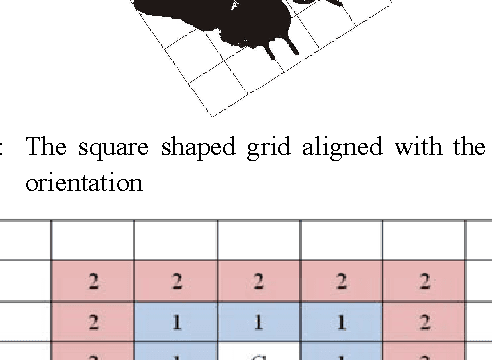

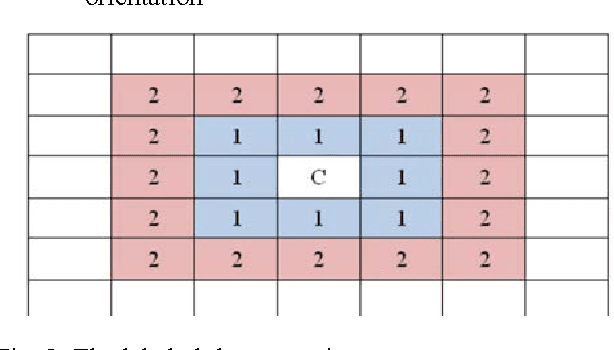
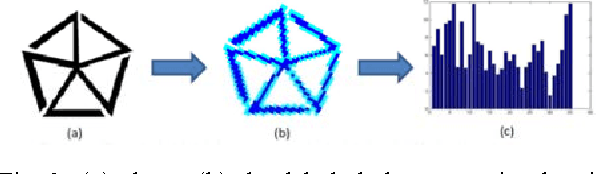
Retrieving similar images from a large dataset based on the image content has been a very active research area and is a very challenging task. Studies have shown that retrieving similar images based on their shape is a very effective method. For this purpose a large number of methods exist in literature. The combination of more than one feature has also been investigated for this purpose and has shown promising results. In this paper a fusion based shapes recognition method has been proposed. A set of local boundary based and region based features are derived from the labeled grid based representation of the shape and are combined with a few global shape features to produce a composite shape descriptor. This composite shape descriptor is then used in a weighted ranking algorithm to find similarities among shapes from a large dataset. The experimental analysis has shown that the proposed method is powerful enough to discriminate the geometrically similar shapes from the non-similar ones.
Fast Algorithms for Mining Interesting Frequent Itemsets without Minimum Support
Apr 21, 2009



Real world datasets are sparse, dirty and contain hundreds of items. In such situations, discovering interesting rules (results) using traditional frequent itemset mining approach by specifying a user defined input support threshold is not appropriate. Since without any domain knowledge, setting support threshold small or large can output nothing or a large number of redundant uninteresting results. Recently a novel approach of mining only N-most/Top-K interesting frequent itemsets has been proposed, which discovers the top N interesting results without specifying any user defined support threshold. However, mining interesting frequent itemsets without minimum support threshold are more costly in terms of itemset search space exploration and processing cost. Thereby, the efficiency of their mining highly depends upon three main factors (1) Database representation approach used for itemset frequency counting, (2) Projection of relevant transactions to lower level nodes of search space and (3) Algorithm implementation technique. Therefore, to improve the efficiency of mining process, in this paper we present two novel algorithms called (N-MostMiner and Top-K-Miner) using the bit-vector representation approach which is very efficient in terms of itemset frequency counting and transactions projection. In addition to this, several efficient implementation techniques of N-MostMiner and Top-K-Miner are also present which we experienced in our implementation. Our experimental results on benchmark datasets suggest that the NMostMiner and Top-K-Miner are very efficient in terms of processing time as compared to current best algorithms BOMO and TFP.