 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Learning for Remote Sensing Data
Dec 24, 2023Deep learning has had remarkable success at analyzing handheld imagery such as consumer photos due to the availability of large-scale human annotations (e.g., ImageNet). However, remote sensing data lacks such extensive annotation and thus potential for supervised learning. To address this, we propose a highly effective semi-supervised approach tailored specifically to remote sensing data. Our approach encompasses two key contributions. First, we adapt the FixMatch framework to remote sensing data by designing robust strong and weak augmentations suitable for this domain. Second, we develop an effective semi-supervised learning method by removing bias in imbalanced training data resulting from both actual labels and pseudo-labels predicted by the model. Our simple semi-supervised framework was validated by extensive experimentation. Using 30\% of labeled annotations, it delivers a 7.1\% accuracy gain over the supervised learning baseline and a 2.1\% gain over the supervised state-of-the-art CDS method on the remote sensing xView dataset.
Multi-Spectral Image Classification with Ultra-Lean Complex-Valued Models
Nov 21, 2022
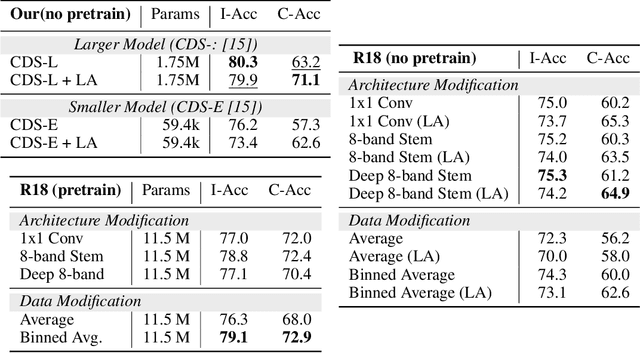
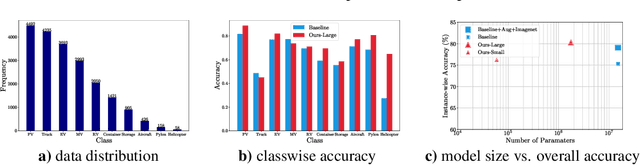
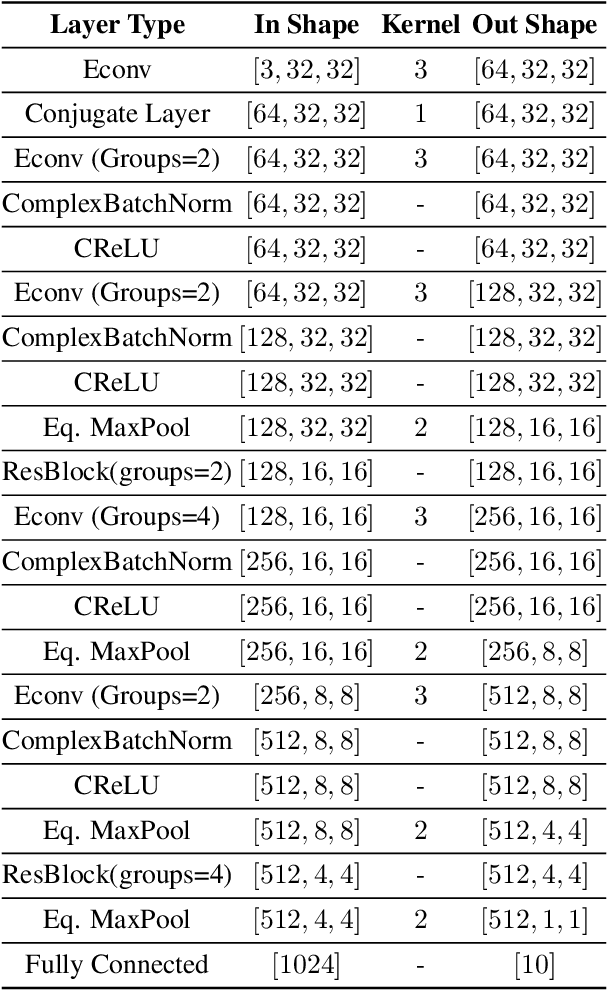
Multi-spectral imagery is invaluable for remote sensing due to different spectral signatures exhibited by materials that often appear identical in greyscale and RGB imagery. Paired with modern deep learning methods, this modality has great potential utility in a variety of remote sensing applications, such as humanitarian assistance and disaster recovery efforts. State-of-the-art deep learning methods have greatly benefited from large-scale annotations like in ImageNet, but existing MSI image datasets lack annotations at a similar scale. As an alternative to transfer learning on such data with few annotations, we apply complex-valued co-domain symmetric models to classify real-valued MSI images. Our experiments on 8-band xView data show that our ultra-lean model trained on xView from scratch without data augmentations can outperform ResNet with data augmentation and modified transfer learning on xView. Our work is the first to demonstrate the value of complex-valued deep learning on real-valued MSI data.
Unsupervised Feature Learning in Remote Sensing
Aug 07, 2019
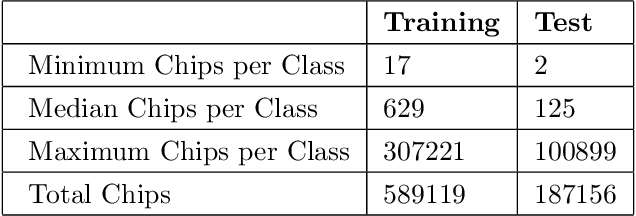
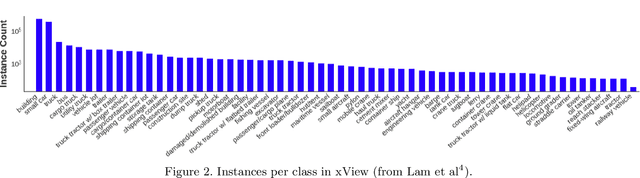
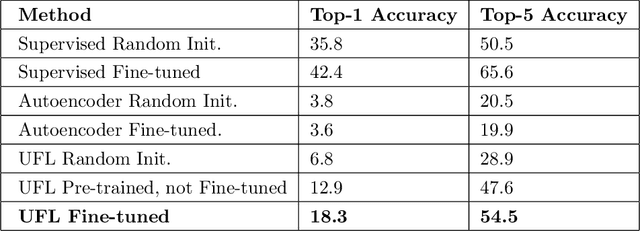
The need for labeled data is among the most common and well-known practical obstacles to deploying deep learning algorithms to solve real-world problems. The current generation of learning algorithms requires a large volume of data labeled according to a static and pre-defined schema. Conversely, humans can quickly learn generalizations based on large quantities of unlabeled data, and turn these generalizations into classifications using spontaneous labels, often including labels not seen before. We apply a state-of-the-art unsupervised learning algorithm to the noisy and extremely imbalanced xView data set to train a feature extractor that adapts to several tasks: visual similarity search that performs well on both common and rare classes; identifying outliers within a labeled data set; and learning a natural class hierarchy automatically.