 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
Mar 12, 2026Multi-modal large language models (MLLMs) have advanced general-purpose video understanding but struggle with long, high-resolution videos -- they process every pixel equally in their vision transformers (ViTs) or LLMs despite significant spatiotemporal redundancy. We introduce AutoGaze, a lightweight module that removes redundant patches before processed by a ViT or an MLLM. Trained with next-token prediction and reinforcement learning, AutoGaze autoregressively selects a minimal set of multi-scale patches that can reconstruct the video within a user-specified error threshold, eliminating redundancy while preserving information. Empirically, AutoGaze reduces visual tokens by 4x-100x and accelerates ViTs and MLLMs by up to 19x, enabling scaling MLLMs to 1K-frame 4K-resolution videos and achieving superior results on video benchmarks (e.g., 67.0% on VideoMME). Furthermore, we introduce HLVid: the first high-resolution, long-form video QA benchmark with 5-minute 4K-resolution videos, where an MLLM scaled with AutoGaze improves over the baseline by 10.1% and outperforms the previous best MLLM by 4.5%. Project page: https://autogaze.github.io/.
Efficient In-Domain Question Answering for Resource-Constrained Environments
Sep 26, 2024Retrieval Augmented Generation (RAG) is a common method for integrating external knowledge into pretrained Large Language Models (LLMs) to enhance accuracy and relevancy in question answering (QA) tasks. However, prompt engineering and resource efficiency remain significant bottlenecks in developing optimal and robust RAG solutions for real-world QA applications. Recent studies have shown success in using fine tuning to address these problems; in particular, Retrieval Augmented Fine Tuning (RAFT) applied to smaller 7B models has demonstrated superior performance compared to RAG setups with much larger models such as GPT-3.5. The combination of RAFT with parameter-efficient fine tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA), promises an even more efficient solution, yet remains an unexplored area. In this work, we combine RAFT with LoRA to reduce fine tuning and storage requirements and gain faster inference times while maintaining comparable RAG performance. This results in a more compute-efficient RAFT, or CRAFT, which is particularly useful for knowledge-intensive QA tasks in resource-constrained environments where internet access may be restricted and hardware resources limited.
Debiased Learning for Remote Sensing Data
Dec 24, 2023Deep learning has had remarkable success at analyzing handheld imagery such as consumer photos due to the availability of large-scale human annotations (e.g., ImageNet). However, remote sensing data lacks such extensive annotation and thus potential for supervised learning. To address this, we propose a highly effective semi-supervised approach tailored specifically to remote sensing data. Our approach encompasses two key contributions. First, we adapt the FixMatch framework to remote sensing data by designing robust strong and weak augmentations suitable for this domain. Second, we develop an effective semi-supervised learning method by removing bias in imbalanced training data resulting from both actual labels and pseudo-labels predicted by the model. Our simple semi-supervised framework was validated by extensive experimentation. Using 30\% of labeled annotations, it delivers a 7.1\% accuracy gain over the supervised learning baseline and a 2.1\% gain over the supervised state-of-the-art CDS method on the remote sensing xView dataset.
Unsupervised Feature Learning in Remote Sensing
Aug 07, 2019
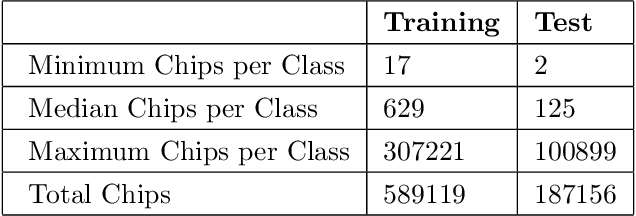
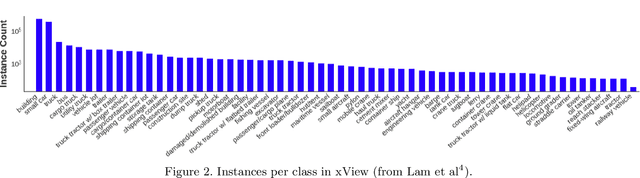
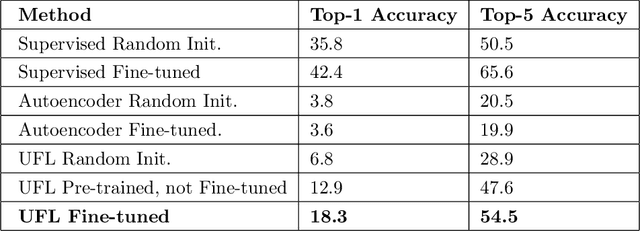
The need for labeled data is among the most common and well-known practical obstacles to deploying deep learning algorithms to solve real-world problems. The current generation of learning algorithms requires a large volume of data labeled according to a static and pre-defined schema. Conversely, humans can quickly learn generalizations based on large quantities of unlabeled data, and turn these generalizations into classifications using spontaneous labels, often including labels not seen before. We apply a state-of-the-art unsupervised learning algorithm to the noisy and extremely imbalanced xView data set to train a feature extractor that adapts to several tasks: visual similarity search that performs well on both common and rare classes; identifying outliers within a labeled data set; and learning a natural class hierarchy automatically.