 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-Net: AutofoCus-Enhanced Convolutional Network for Field Imperfection Estimation with application to high b-value spiral Diffusion MRI
Nov 21, 2024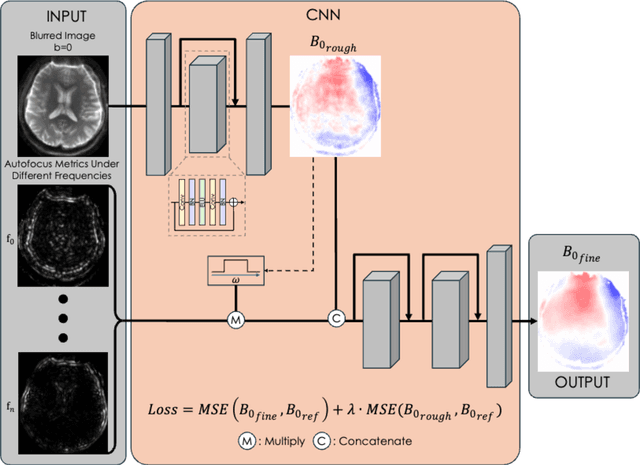
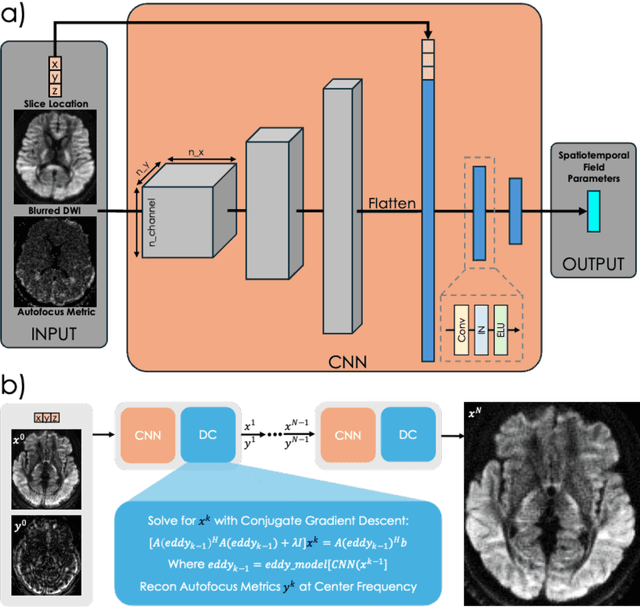
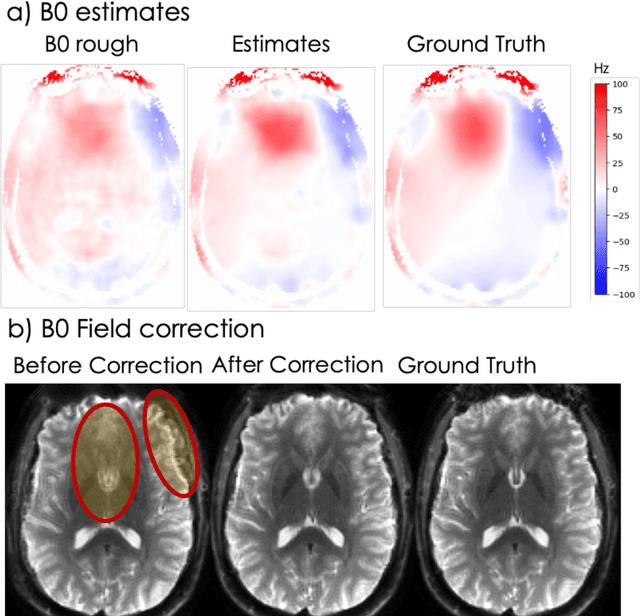
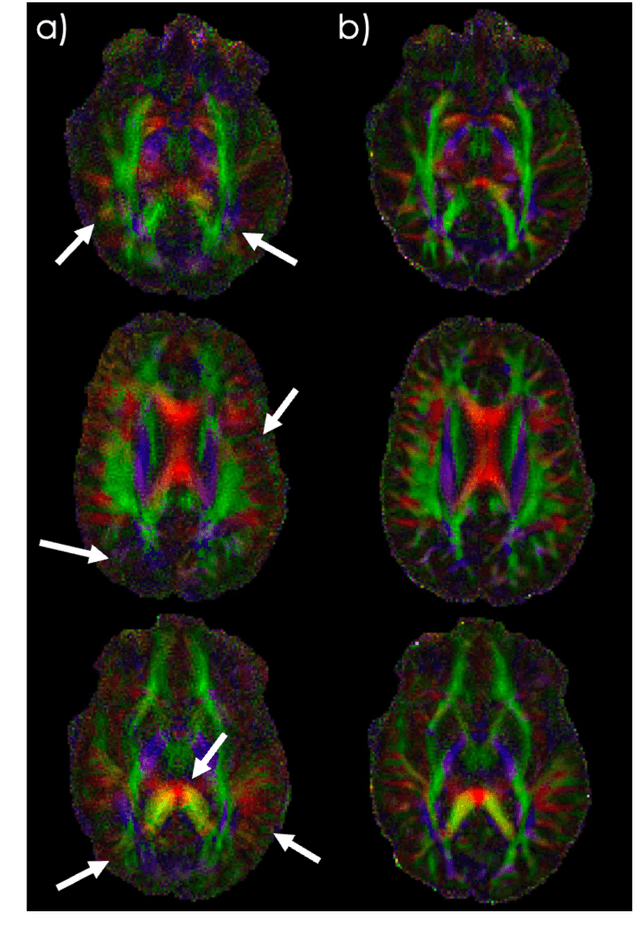
Spatiotemporal magnetic field variations from B0-inhomogeneity and diffusion-encoding-induced eddy-currents can be detrimental to rapid image-encoding schemes such as spiral, EPI and 3D-cones, resulting in undesirable image artifacts. In this work, a data driven approach for automatic estimation of these field imperfections is developed by combining autofocus metrics with deep learning, and by leveraging a compact basis representation of the expected field imperfections. The method was applied to single-shot spiral diffusion MRI at high b-values where accurate estimation of B0 and eddy were obtained, resulting in high quality image reconstruction without need for additional external calibrations.
Accelerating Longitudinal MRI using Prior Informed Latent Diffusion
Jun 29, 2024



MRI is a widely used ionization-free soft-tissue imaging modality, often employed repeatedly over a patient's lifetime. However, prolonged scanning durations, among other issues, can limit availability and accessibility. In this work, we aim to substantially reduce scan times by leveraging prior scans of the same patient. These prior scans typically contain considerable shared information with the current scan, thereby enabling higher acceleration rates when appropriately utilized. We propose a prior informed reconstruction method with a trained diffusion model in conjunction with data-consistency steps. Our method can be trained with unlabeled image data, eliminating the need for a dataset of either k-space measurements or paired longitudinal scans as is required of other learning-based methods. We demonstrate superiority of our method over previously suggested approaches in effectively utilizing prior information without over-biasing prior consistency, which we validate on both an open-source dataset of healthy patients as well as several longitudinal cases of clinical interest.
Subtractive Training for Music Stem Insertion using Latent Diffusion Models
Jun 27, 2024We present Subtractive Training, a simple and novel method for synthesizing individual musical instrument stems given other instruments as context. This method pairs a dataset of complete music mixes with 1) a variant of the dataset lacking a specific stem, and 2) LLM-generated instructions describing how the missing stem should be reintroduced. We then fine-tune a pretrained text-to-audio diffusion model to generate the missing instrument stem, guided by both the existing stems and the text instruction. Our results demonstrate Subtractive Training's efficacy in creating authentic drum stems that seamlessly blend with the existing tracks. We also show that we can use the text instruction to control the generation of the inserted stem in terms of rhythm, dynamics, and genre, allowing us to modify the style of a single instrument in a full song while keeping the remaining instruments the same. Lastly, we extend this technique to MIDI formats, successfully generating compatible bass, drum, and guitar parts for incomplete arrangements.