 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Control under Time-Varying Environment
Jun 06, 2022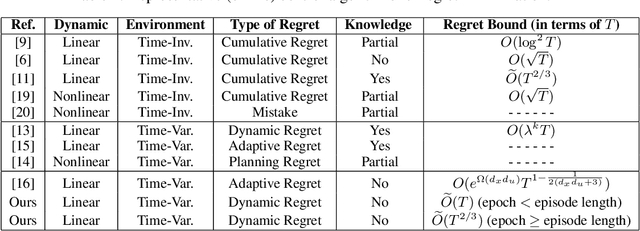
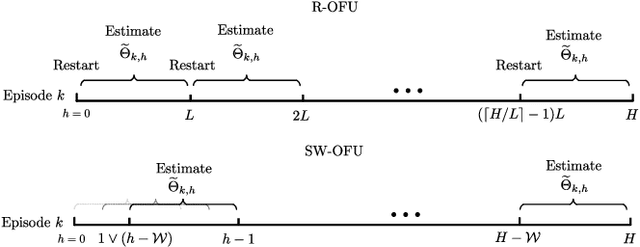
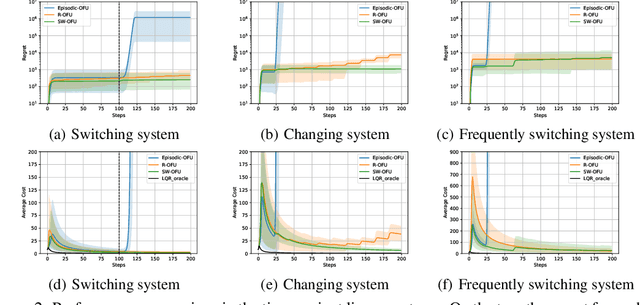
This paper investigates the problem of regret minimization in linear time-varying (LTV) dynamical systems. Due to the simultaneous presence of uncertainty and non-stationarity, designing online control algorithms for unknown LTV systems remains a challenging task. At a cost of NP-hard offline planning, prior works have introduced online convex optimization algorithms, although they suffer from nonparametric rate of regret. In this paper, we propose the first computationally tractable online algorithm with regret guarantees that avoids offline planning over the state linear feedback policies. Our algorithm is based on the optimism in the face of uncertainty (OFU) principle in which we optimistically select the best model in a high confidence region. Our algorithm is then more explorative when compared to previous approaches. To overcome non-stationarity, we propose either a restarting strategy (R-OFU) or a sliding window (SW-OFU) strategy. With proper configuration, our algorithm is attains sublinear regret $O(T^{2/3})$. These algorithms utilize data from the current phase for tracking variations on the system dynamics. We corroborate our theoretical findings with numerical experiments, which highlight the effectiveness of our methods. To the best of our knowledge, our study establishes the first model-based online algorithm with regret guarantees under LTV dynamical systems.