 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDark-ISP: Enhancing RAW Image Processing for Low-Light Object Detection
Sep 11, 2025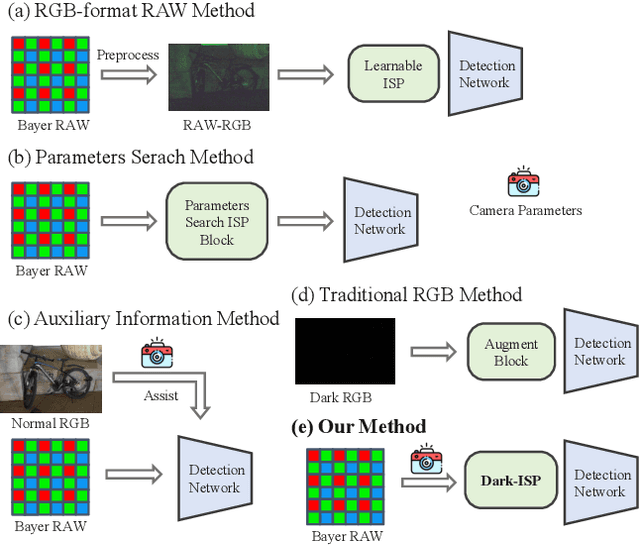
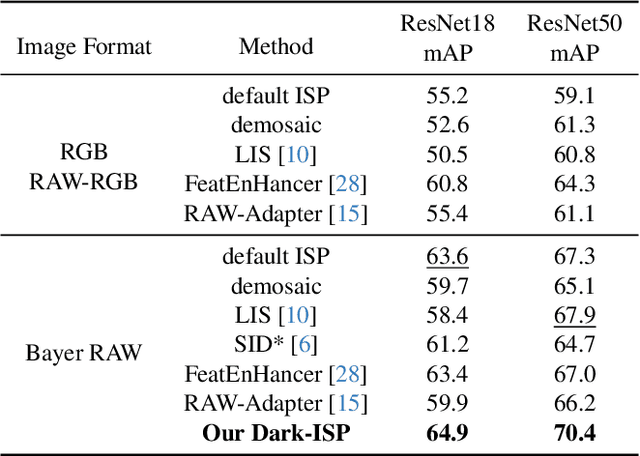
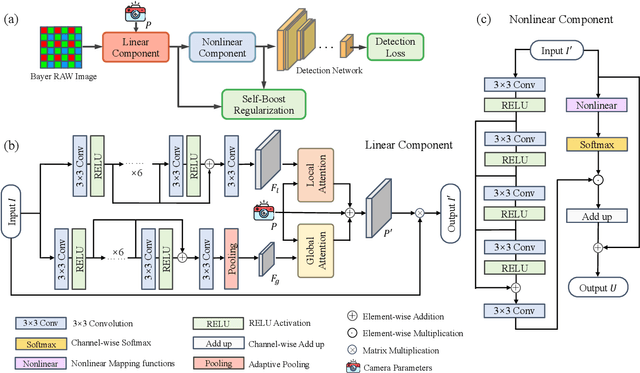
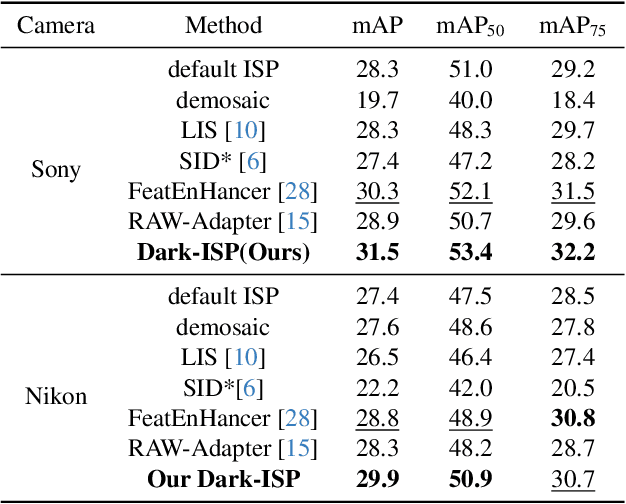
Low-light Object detection is crucial for many real-world applications but remains challenging due to degraded image quality. While recent studies have shown that RAW images offer superior potential over RGB images, existing approaches either use RAW-RGB images with information loss or employ complex frameworks. To address these, we propose a lightweight and self-adaptive Image Signal Processing (ISP) plugin, Dark-ISP, which directly processes Bayer RAW images in dark environments, enabling seamless end-to-end training for object detection. Our key innovations are: (1) We deconstruct conventional ISP pipelines into sequential linear (sensor calibration) and nonlinear (tone mapping) sub-modules, recasting them as differentiable components optimized through task-driven losses. Each module is equipped with content-aware adaptability and physics-informed priors, enabling automatic RAW-to-RGB conversion aligned with detection objectives. (2) By exploiting the ISP pipeline's intrinsic cascade structure, we devise a Self-Boost mechanism that facilitates cooperation between sub-modules. Through extensive experiments on three RAW image datasets, we demonstrate that our method outperforms state-of-the-art RGB- and RAW-based detection approaches, achieving superior results with minimal parameters in challenging low-light environments.
* 11 pages, 6 figures, conference
PointSSC: A Cooperative Vehicle-Infrastructure Point Cloud Benchmark for Semantic Scene Completion
Sep 22, 2023



Semantic Scene Completion (SSC) aims to jointly generate space occupancies and semantic labels for complex 3D scenes. Most existing SSC models focus on volumetric representations, which are memory-inefficient for large outdoor spaces. Point clouds provide a lightweight alternative but existing benchmarks lack outdoor point cloud scenes with semantic labels. To address this, we introduce PointSSC, the first cooperative vehicle-infrastructure point cloud benchmark for semantic scene completion. These scenes exhibit long-range perception and minimal occlusion. We develop an automated annotation pipeline leveraging Segment Anything to efficiently assign semantics. To benchmark progress, we propose a LiDAR-based model with a Spatial-Aware Transformer for global and local feature extraction and a Completion and Segmentation Cooperative Module for joint completion and segmentation. PointSSC provides a challenging testbed to drive advances in semantic point cloud completion for real-world navigation.