 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Fabrication Fidelity of Integrated Nanophotonic Devices Using Deep Learning
Mar 21, 2023Next-generation integrated nanophotonic device designs leverage advanced optimization techniques such as inverse design and topology optimization which achieve high performance and extreme miniaturization by optimizing a massively complex design space enabled by small feature sizes. However, unless the optimization is heavily constrained, the generated small features are not reliably fabricated, leading to optical performance degradation. Even for simpler, conventional designs, fabrication-induced performance degradation still occurs. The degree of deviation from the original design not only depends on the size and shape of its features, but also on the distribution of features and the surrounding environment, presenting complex, proximity-dependent behavior. Without proprietary fabrication process specifications, design corrections can only be made after calibrating fabrication runs take place. In this work, we introduce a general deep machine learning model that automatically corrects photonic device design layouts prior to first fabrication. Only a small set of scanning electron microscopy images of engineered training features are required to create the deep learning model. With correction, the outcome of the fabricated layout is closer to what is intended, and thus so too is the performance of the design. Without modifying the nanofabrication process, adding significant computation in design, or requiring proprietary process specifications, we believe our model opens the door to new levels of reliability and performance in next-generation photonic circuits.
PCA-Boosted Autoencoders for Nonlinear Dimensionality Reduction in Low Data Regimes
May 23, 2022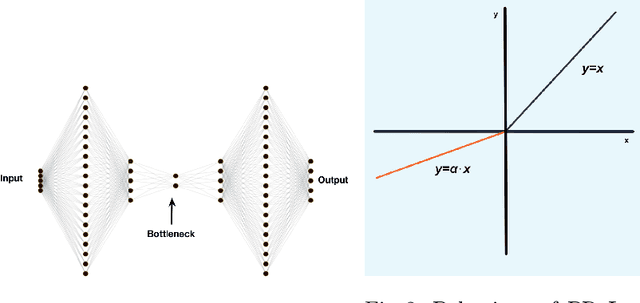
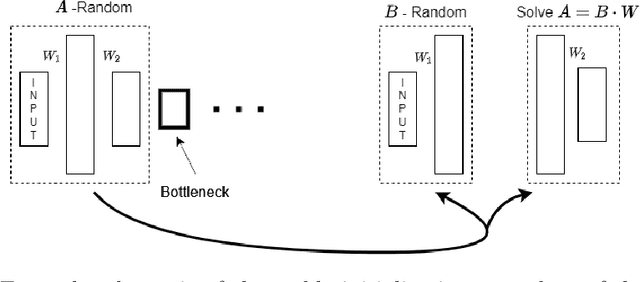
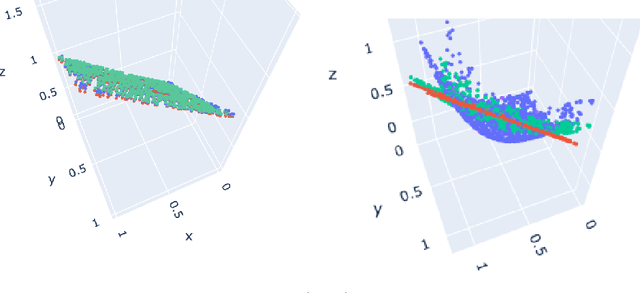
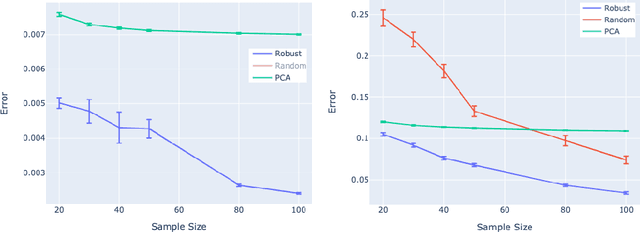
Autoencoders (AE) provide a useful method for nonlinear dimensionality reduction but are ill-suited for low data regimes. Conversely, Principal Component Analysis (PCA) is data-efficient but is limited to linear dimensionality reduction, posing a problem when data exhibits inherent nonlinearity. This presents a challenge in various scientific and engineering domains such as the nanophotonic component design, where data exhibits nonlinear features while being expensive to obtain due to costly real measurements or resource-consuming solutions of partial differential equations. To address this difficulty, we propose a technique that harnesses the best of both worlds: an autoencoder that leverages PCA to perform well on scarce nonlinear data. Specifically, we outline a numerically robust PCA-based initialization of AE, which, together with the parameterized ReLU activation function, allows the training process to start from an exact PCA solution and improve upon it. A synthetic example is presented first to study the effects of data nonlinearity and size on the performance of the proposed method. We then evaluate our method on several nanophotonic component design problems where obtaining useful data is expensive. To demonstrate universality, we also apply it to tasks in other scientific domains: a benchmark breast cancer dataset and a gene expression dataset. We show that our proposed approach is substantially better than both PCA and randomly initialized AE in the majority of low-data regime cases we consider, or at least is comparable to the best of either of the other two methods.
Bellman Error Based Feature Generation using Random Projections on Sparse Spaces
Sep 21, 2012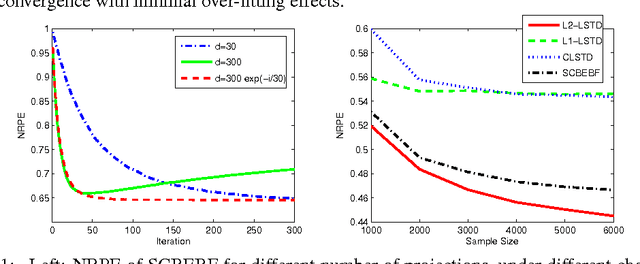
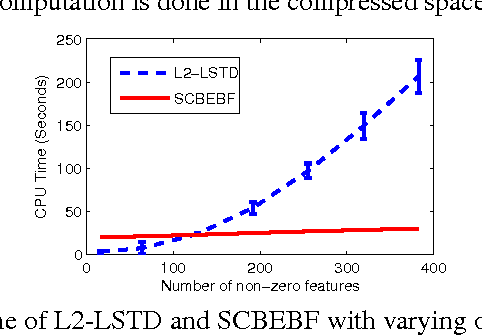
We address the problem of automatic generation of features for value function approximation. Bellman Error Basis Functions (BEBFs) have been shown to improve the error of policy evaluation with function approximation, with a convergence rate similar to that of value iteration. We propose a simple, fast and robust algorithm based on random projections to generate BEBFs for sparse feature spaces. We provide a finite sample analysis of the proposed method, and prove that projections logarithmic in the dimension of the original space are enough to guarantee contraction in the error. Empirical results demonstrate the strength of this method.