 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Offline Reinforcement Learning with Transformers for Sequential Recommendation
Jul 26, 2023
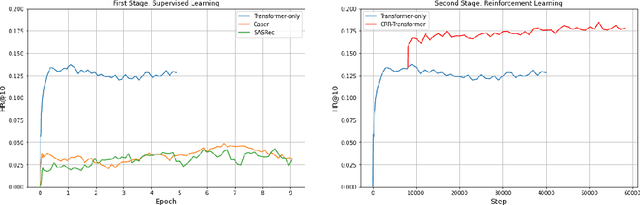

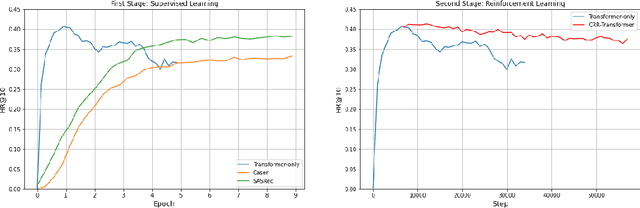
We consider the problem of sequential recommendation, where the current recommendation is made based on past interactions. This recommendation task requires efficient processing of the sequential data and aims to provide recommendations that maximize the long-term reward. To this end, we train a farsighted recommender by using an offline RL algorithm with the policy network in our model architecture that has been initialized from a pre-trained transformer model. The pre-trained model leverages the superb ability of the transformer to process sequential information. Compared to prior works that rely on online interaction via simulation, we focus on implementing a fully offline RL framework that is able to converge in a fast and stable way. Through extensive experiments on public datasets, we show that our method is robust across various recommendation regimes, including e-commerce and movie suggestions. Compared to state-of-the-art supervised learning algorithms, our algorithm yields recommendations of higher quality, demonstrating the clear advantage of combining RL and transformers.