 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-space Contrastive Guidance for Efficient Hallucination Mitigation in LVLMs
Jan 20, 2026Hallucinations in large vision-language models (LVLMs) often arise when language priors dominate over visual evidence, causing object misidentification and visually inconsistent descriptions. We address this issue by framing hallucination mitigation as contrastive guidance, steering generation toward visually grounded and semantically faithful text. This approach regulates the model's internal behavior by reducing over-dependence on language priors and contrasting visually grounded with language-only representations. We propose Attention-space Contrastive Guidance (ACG), a single-pass mechanism that operates within self-attention layers to construct both vision-language and language-only attention paths in a single forward computation. This integration enables computationally efficient guidance directly embedded in the model's representation contextualization. To correct approximation bias introduced by the single-pass formulation, we further apply an orthogonalized correction that removes components aligned with the language-only path, selectively amplifying visual contributions. Experiments on the CHAIR and POPE benchmarks show that ACG achieves state-of-the-art faithfulness and caption quality while significantly reducing computational cost. Our method establishes a principled and efficient alternative, reducing latency by up to 2x compared to prior contrastive decoding methods that require multiple forward passes.
Retaining and Enhancing Pre-trained Knowledge in Vision-Language Models with Prompt Ensembling
Dec 10, 2024



The advancement of vision-language models, particularly the Contrastive Language-Image Pre-training (CLIP) model, has revolutionized the field of machine learning by enabling robust zero-shot learning capabilities. These capabilities allow models to understand and respond to previously unseen data without task-specific training. However, adapting CLIP to integrate specialized knowledge from various domains while retaining its zero-shot capabilities remains a significant challenge. To address this, we introduce a novel prompt ensemble learning approach called Group-wise Prompt Ensemble (GPE). This method aims to enhance CLIP's zero-shot capabilities by incorporating new domain knowledge while improving its adaptability and robustness against data distribution shifts. Our approach hinges on three main strategies: prompt grouping with masked attention to optimize CLIP's adaptability while safeguarding its zero-shot capabilities; the incorporation of auxiliary prompts for the seamless integration of new domain insights without disrupting the original model's representation; and an ensemble learning strategy that effectively merges original and new knowledge. Through rigorous experimentation, including more challenging cross-dataset transfer evaluations, our GPE method redefines the benchmarks for the adaptability and efficiency of vision-language models, surpassing existing models across various scenarios.
Exploiting Multi-Modal Features From Pre-trained Networks for Alzheimer's Dementia Recognition
Sep 09, 2020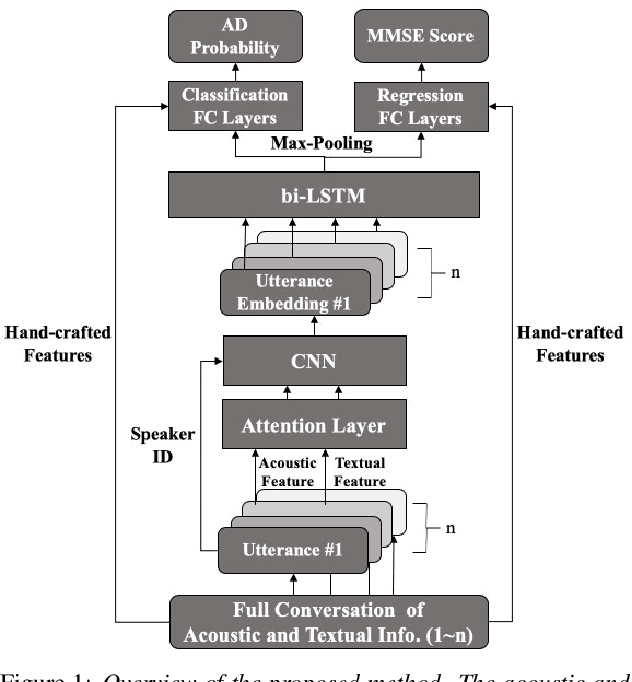

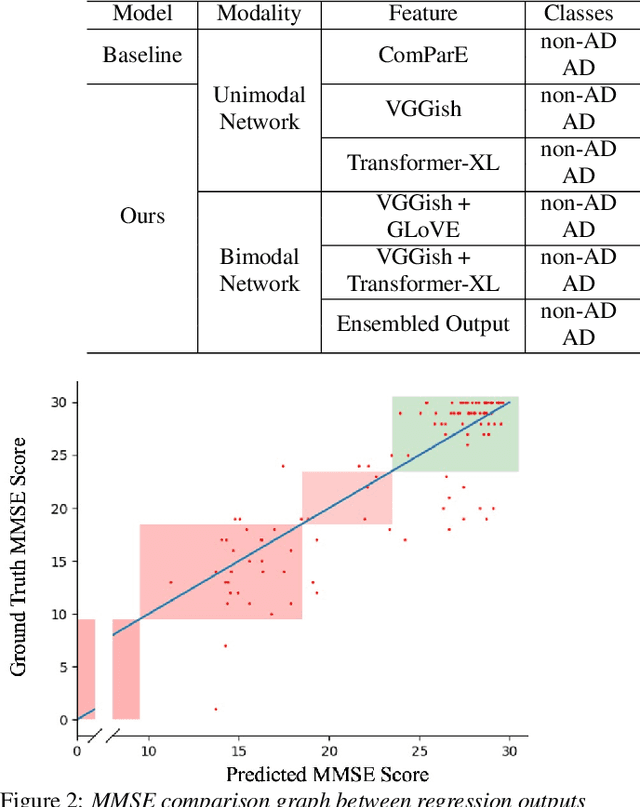
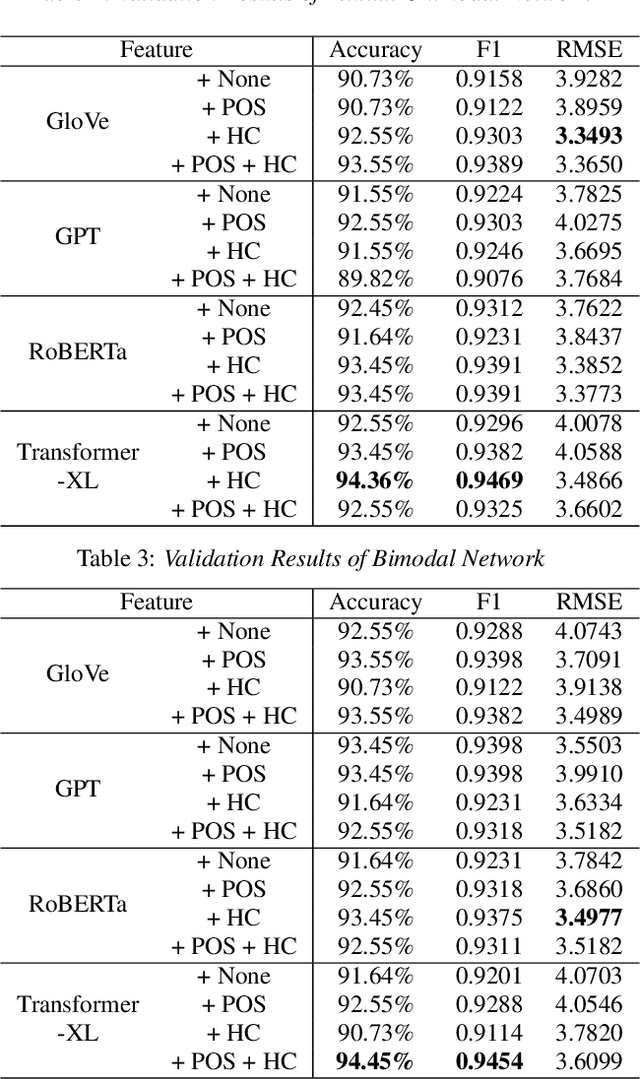
Collecting and accessing a large amount of medical data is very time-consuming and laborious, not only because it is difficult to find specific patients but also because it is required to resolve the confidentiality of a patient's medical records. On the other hand, there are deep learning models, trained on easily collectible, large scale datasets such as Youtube or Wikipedia, offering useful representations. It could therefore be very advantageous to utilize the features from these pre-trained networks for handling a small amount of data at hand. In this work, we exploit various multi-modal features extracted from pre-trained networks to recognize Alzheimer's Dementia using a neural network, with a small dataset provided by the ADReSS Challenge at INTERSPEECH 2020. The challenge regards to discern patients suspicious of Alzheimer's Dementia by providing acoustic and textual data. With the multi-modal features, we modify a Convolutional Recurrent Neural Network based structure to perform classification and regression tasks simultaneously and is capable of computing conversations with variable lengths. Our test results surpass baseline's accuracy by 18.75%, and our validation result for the regression task shows the possibility of classifying 4 classes of cognitive impairment with an accuracy of 78.70%.