 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetaining and Enhancing Pre-trained Knowledge in Vision-Language Models with Prompt Ensembling
Dec 10, 2024



The advancement of vision-language models, particularly the Contrastive Language-Image Pre-training (CLIP) model, has revolutionized the field of machine learning by enabling robust zero-shot learning capabilities. These capabilities allow models to understand and respond to previously unseen data without task-specific training. However, adapting CLIP to integrate specialized knowledge from various domains while retaining its zero-shot capabilities remains a significant challenge. To address this, we introduce a novel prompt ensemble learning approach called Group-wise Prompt Ensemble (GPE). This method aims to enhance CLIP's zero-shot capabilities by incorporating new domain knowledge while improving its adaptability and robustness against data distribution shifts. Our approach hinges on three main strategies: prompt grouping with masked attention to optimize CLIP's adaptability while safeguarding its zero-shot capabilities; the incorporation of auxiliary prompts for the seamless integration of new domain insights without disrupting the original model's representation; and an ensemble learning strategy that effectively merges original and new knowledge. Through rigorous experimentation, including more challenging cross-dataset transfer evaluations, our GPE method redefines the benchmarks for the adaptability and efficiency of vision-language models, surpassing existing models across various scenarios.
Missing Modality Prediction for Unpaired Multimodal Learning via Joint Embedding of Unimodal Models
Jul 17, 2024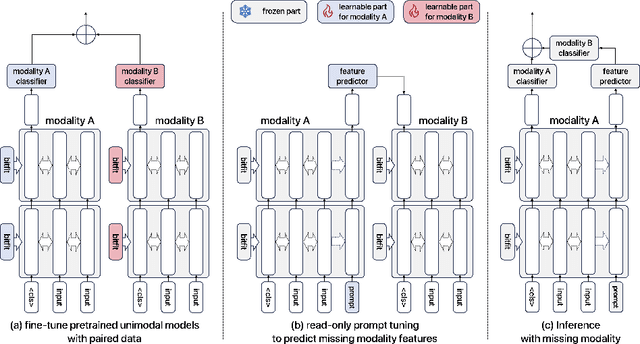
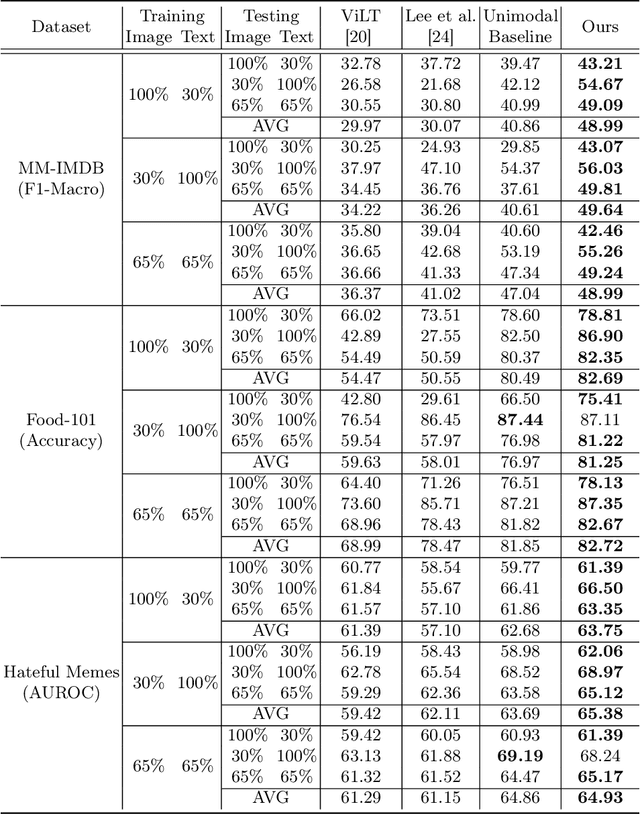
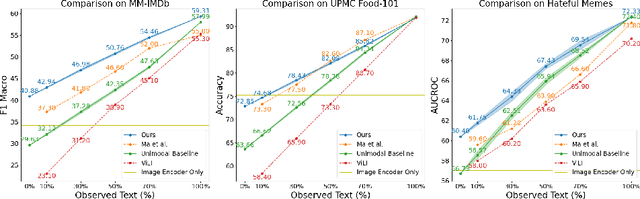
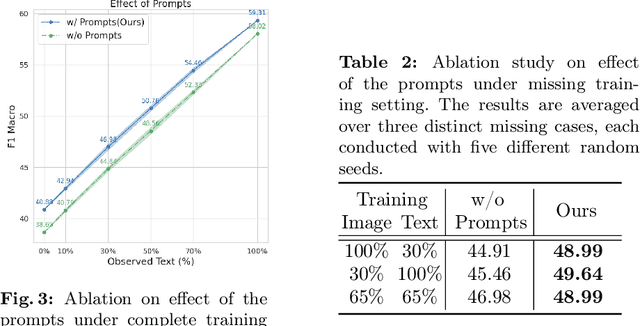
Multimodal learning typically relies on the assumption that all modalities are fully available during both the training and inference phases. However, in real-world scenarios, consistently acquiring complete multimodal data presents significant challenges due to various factors. This often leads to the issue of missing modalities, where data for certain modalities are absent, posing considerable obstacles not only for the availability of multimodal pretrained models but also for their fine-tuning and the preservation of robustness in downstream tasks. To address these challenges, we propose a novel framework integrating parameter-efficient fine-tuning of unimodal pretrained models with a self-supervised joint-embedding learning method. This framework enables the model to predict the embedding of a missing modality in the representation space during inference. Our method effectively predicts the missing embedding through prompt tuning, leveraging information from available modalities. We evaluate our approach on several multimodal benchmark datasets and demonstrate its effectiveness and robustness across various scenarios of missing modalities.
Emotional Brain State Classification on fMRI Data Using Deep Residual and Convolutional Networks
Oct 31, 2022

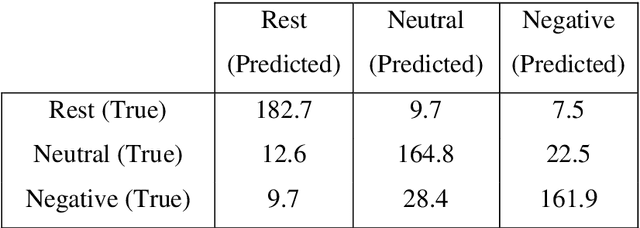

The goal of emotional brain state classification on functional MRI (fMRI) data is to recognize brain activity patterns related to specific emotion tasks performed by subjects during an experiment. Distinguishing emotional brain states from other brain states using fMRI data has proven to be challenging due to two factors: a difficulty to generate fast yet accurate predictions in short time frames, and a difficulty to extract emotion features which generalize to unseen subjects. To address these challenges, we conducted an experiment in which 22 subjects viewed pictures designed to stimulate either negative, neutral or rest emotional responses while their brain activity was measured using fMRI. We then developed two distinct Convolution-based approaches to decode emotional brain states using only spatial information from single, minimally pre-processed (slice timing and realignment) fMRI volumes. In our first approach, we trained a 1D Convolutional Network (84.9% accuracy; chance level 33%) to classify 3 emotion conditions using One-way Analysis of Variance (ANOVA) voxel selection combined with hyperalignment. In our second approach, we trained a 3D ResNet-50 model (78.0% accuracy; chance level 50%) to classify 2 emotion conditions from single 3D fMRI volumes directly. Our Convolutional and Residual classifiers successfully learned group-level emotion features and could decode emotion conditions from fMRI volumes in milliseconds. These approaches could potentially be used in brain computer interfaces and real-time fMRI neurofeedback research.