 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-based Positional Representation for Long Context
Feb 04, 2025In the realm of large-scale language models, a significant challenge arises when extrapolating sequences beyond the maximum allowable length. This is because the model's position embedding mechanisms are limited to positions encountered during training, thus preventing effective representation of positions in longer sequences. We analyzed conventional position encoding methods for long contexts and found the following characteristics. (1) When the representation dimension is regarded as the time axis, Rotary Position Embedding (RoPE) can be interpreted as a restricted wavelet transform using Haar-like wavelets. However, because it uses only a fixed scale parameter, it does not fully exploit the advantages of wavelet transforms, which capture the fine movements of non-stationary signals using multiple scales (window sizes). This limitation could explain why RoPE performs poorly in extrapolation. (2) Previous research as well as our own analysis indicates that Attention with Linear Biases (ALiBi) functions similarly to windowed attention, using windows of varying sizes. However, it has limitations in capturing deep dependencies because it restricts the receptive field of the model. From these insights, we propose a new position representation method that captures multiple scales (i.e., window sizes) by leveraging wavelet transforms without limiting the model's attention field. Experimental results show that this new method improves the performance of the model in both short and long contexts. In particular, our method allows extrapolation of position information without limiting the model's attention field.
Using Perturbed Length-aware Positional Encoding for Non-autoregressive Neural Machine Translation
Jul 29, 2021
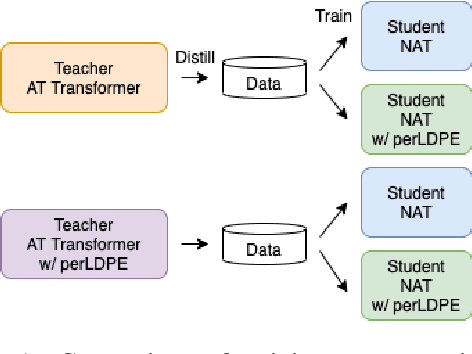

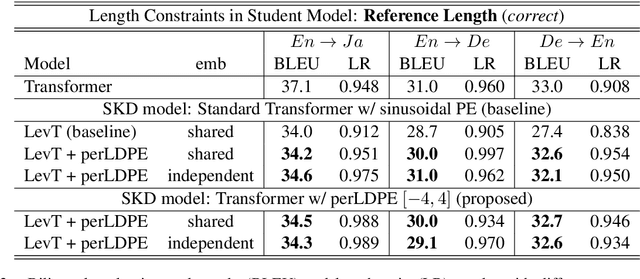
Non-autoregressive neural machine translation (NAT) usually employs sequence-level knowledge distillation using autoregressive neural machine translation (AT) as its teacher model. However, a NAT model often outputs shorter sentences than an AT model. In this work, we propose sequence-level knowledge distillation (SKD) using perturbed length-aware positional encoding and apply it to a student model, the Levenshtein Transformer. Our method outperformed a standard Levenshtein Transformer by 2.5 points in bilingual evaluation understudy (BLEU) at maximum in a WMT14 German to English translation. The NAT model output longer sentences than the baseline NAT models.