 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agents are Social Groups: Investigating Social Influence of Multiple Agents in Human-Agent Interactions
Nov 07, 2024



Multi-agent systems - systems with multiple independent AI agents working together to achieve a common goal - are becoming increasingly prevalent in daily life. Drawing inspiration from the phenomenon of human group social influence, we investigate whether a group of AI agents can create social pressure on users to agree with them, potentially changing their stance on a topic. We conducted a study in which participants discussed social issues with either a single or multiple AI agents, and where the agents either agreed or disagreed with the user's stance on the topic. We found that conversing with multiple agents (holding conversation content constant) increased the social pressure felt by participants, and caused a greater shift in opinion towards the agents' stances on each topic. Our study shows the potential advantages of multi-agent systems over single-agent platforms in causing opinion change. We discuss design implications for possible multi-agent systems that promote social good, as well as the potential for malicious actors to use these systems to manipulate public opinion.
Whodunit? Learning to Contrast for Authorship Attribution
Oct 10, 2022
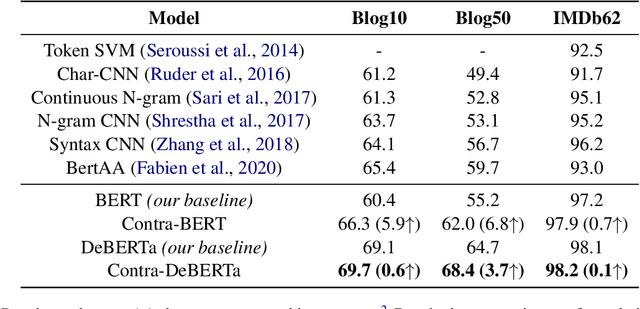
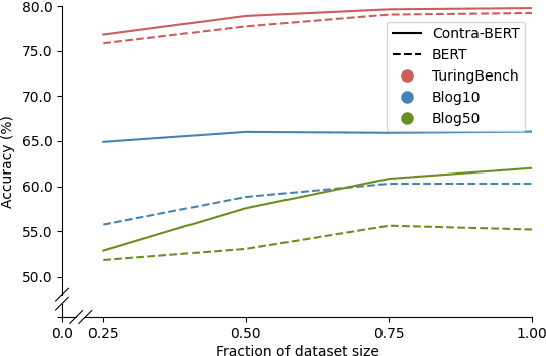

Authorship attribution is the task of identifying the author of a given text. The key is finding representations that can differentiate between authors. Existing approaches typically use manually designed features that capture a dataset's content and style, but these approaches are dataset-dependent and yield inconsistent performance across corpora. In this work, we propose \textit{learning} author-specific representations by fine-tuning pre-trained generic language representations with a contrastive objective (Contra-X). We show that Contra-X learns representations that form highly separable clusters for different authors. It advances the state-of-the-art on multiple human and machine authorship attribution benchmarks, enabling improvements of up to 6.8% over cross-entropy fine-tuning. However, we find that Contra-X improves overall accuracy at the cost of sacrificing performance for some authors. Resolving this tension will be an important direction for future work. To the best of our knowledge, we are the first to integrate contrastive learning with pre-trained language model fine-tuning for authorship attribution.