 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Grafting: Scaling Language Model Pre-training via Offline Conditional Memory
May 20, 2026Scaling conditional memory offers a promising way to increase language-model capacity, but existing methods such as Engram learn large memory tables from scratch during pre-training, making memory scaling expensive and sometimes ineffective. We propose Memory Grafting, a conditional memory scaling method that utilizes frozen hidden states from a grafting model as conditional n-gram memory. Given frequent local n-grams, we run the grafting model offline, store final-token hidden representations as memory values, and let the recipient model retrieve them through exact longest-match suffix lookup. Retrieved memories are adapted by lightweight projections and gates, while a hash-based Engram fallback preserves coverage for unmatched contexts. Since the grafting model is only run offline and exact lookup has expected O(1) complexity with respect to memory-bank size, Memory Grafting expands external latent capacity with limited training and inference overhead. Experiments under matched recipient architectures and pre-training budgets show that Memory Grafting improves over both MoE and vanilla Engram baselines. In the 2.8B-scale setting, it improves the average benchmark score from 51.95 for MoE and 52.43 for vanilla Engram to 53.86. In the 0.92B-scale setting, all grafting-model variants improve over the baselines, with Qwen3.5-35B-A3B giving the strongest gains. These results suggest that pretrained models can serve as reusable constructors of external latent memory, providing a practical step toward scaling future language models beyond trainable parameters alone.
Text-guided Visual Prompt DINO for Generic Segmentation
Aug 08, 2025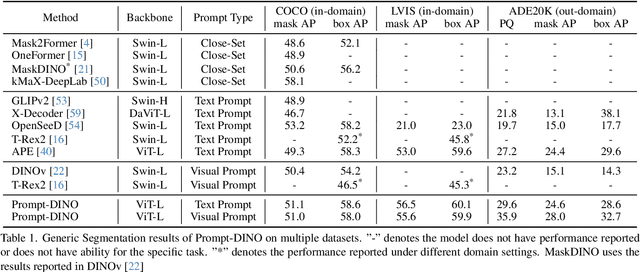
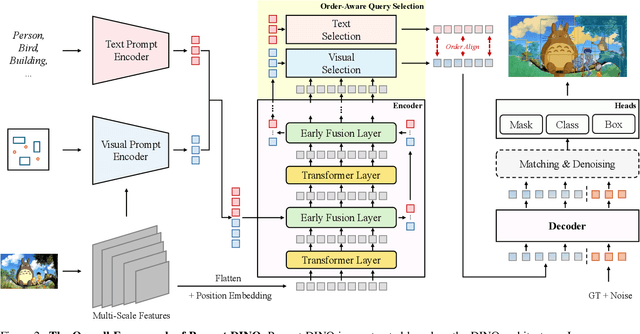
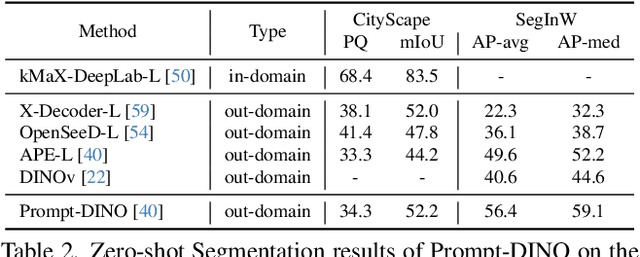
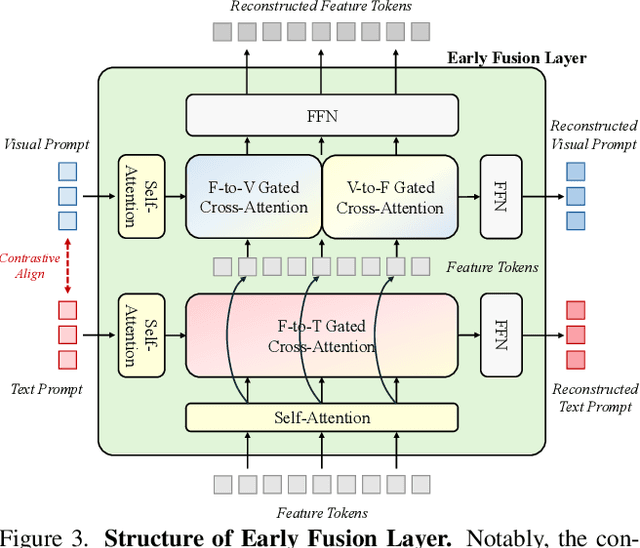
Recent advancements in multimodal vision models have highlighted limitations in late-stage feature fusion and suboptimal query selection for hybrid prompts open-world segmentation, alongside constraints from caption-derived vocabularies. To address these challenges, we propose Prompt-DINO, a text-guided visual Prompt DINO framework featuring three key innovations. First, we introduce an early fusion mechanism that unifies text/visual prompts and backbone features at the initial encoding stage, enabling deeper cross-modal interactions to resolve semantic ambiguities. Second, we design order-aligned query selection for DETR-based architectures, explicitly optimizing the structural alignment between text and visual queries during decoding to enhance semantic-spatial consistency. Third, we develop a generative data engine powered by the Recognize Anything via Prompting (RAP) model, which synthesizes 0.5B diverse training instances through a dual-path cross-verification pipeline, reducing label noise by 80.5% compared to conventional approaches. Extensive experiments demonstrate that Prompt-DINO achieves state-of-the-art performance on open-world detection benchmarks while significantly expanding semantic coverage beyond fixed-vocabulary constraints. Our work establishes a new paradigm for scalable multimodal detection and data generation in open-world scenarios. Data&Code are available at https://github.com/WeChatCV/WeVisionOne.
Kendall's $τ$ Coefficient for Logits Distillation
Sep 26, 2024



Knowledge distillation typically employs the Kullback-Leibler (KL) divergence to constrain the student model's output to match the soft labels provided by the teacher model exactly. However, sometimes the optimization direction of the KL divergence loss is not always aligned with the task loss, where a smaller KL divergence could lead to erroneous predictions that diverge from the soft labels. This limitation often results in suboptimal optimization for the student. Moreover, even under temperature scaling, the KL divergence loss function tends to overly focus on the larger-valued channels in the logits, disregarding the rich inter-class information provided by the multitude of smaller-valued channels. This hard constraint proves too challenging for lightweight students, hindering further knowledge distillation. To address this issue, we propose a plug-and-play ranking loss based on Kendall's $\tau$ coefficient, called Rank-Kendall Knowledge Distillation (RKKD). RKKD balances the attention to smaller-valued channels by constraining the order of channel values in student logits, providing more inter-class relational information. The rank constraint on the top-valued channels helps avoid suboptimal traps during optimization. We also discuss different differentiable forms of Kendall's $\tau$ coefficient and demonstrate that the proposed ranking loss function shares a consistent optimization objective with the KL divergence. Extensive experiments on the CIFAR-100 and ImageNet datasets show that our RKKD can enhance the performance of various knowledge distillation baselines and offer broad improvements across multiple teacher-student architecture combinations.
SDDNet: Style-guided Dual-layer Disentanglement Network for Shadow Detection
Aug 17, 2023



Despite significant progress in shadow detection, current methods still struggle with the adverse impact of background color, which may lead to errors when shadows are present on complex backgrounds. Drawing inspiration from the human visual system, we treat the input shadow image as a composition of a background layer and a shadow layer, and design a Style-guided Dual-layer Disentanglement Network (SDDNet) to model these layers independently. To achieve this, we devise a Feature Separation and Recombination (FSR) module that decomposes multi-level features into shadow-related and background-related components by offering specialized supervision for each component, while preserving information integrity and avoiding redundancy through the reconstruction constraint. Moreover, we propose a Shadow Style Filter (SSF) module to guide the feature disentanglement by focusing on style differentiation and uniformization. With these two modules and our overall pipeline, our model effectively minimizes the detrimental effects of background color, yielding superior performance on three public datasets with a real-time inference speed of 32 FPS.