 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Perplexity and Menger Curvature-Based Approach for Similarity Evaluation of Large Language Models
Apr 08, 2025



The rise of Large Language Models (LLMs) has brought about concerns regarding copyright infringement and unethical practices in data and model usage. For instance, slight modifications to existing LLMs may be used to falsely claim the development of new models, leading to issues of model copying and violations of ownership rights. This paper addresses these challenges by introducing a novel metric for quantifying LLM similarity, which leverages perplexity curves and differences in Menger curvature. Comprehensive experiments validate the performance of our methodology, demonstrating its superiority over baseline methods and its ability to generalize across diverse models and domains. Furthermore, we highlight the capability of our approach in detecting model replication through simulations, emphasizing its potential to preserve the originality and integrity of LLMs. Code is available at https://github.com/zyttt-coder/LLM_similarity.
Self-Improvement Towards Pareto Optimality: Mitigating Preference Conflicts in Multi-Objective Alignment
Feb 20, 2025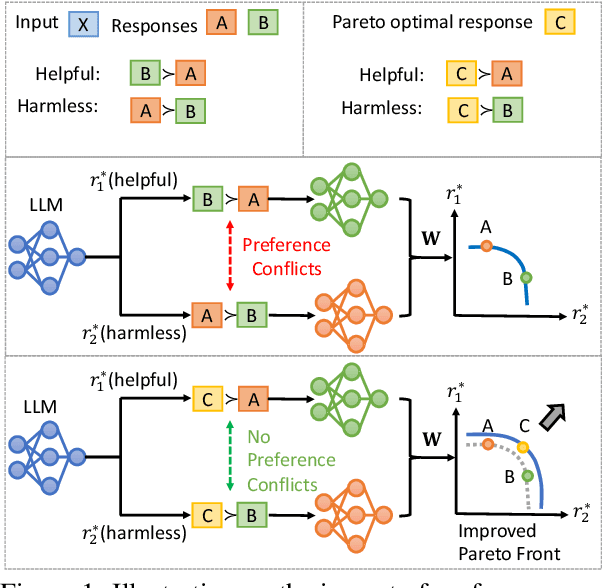
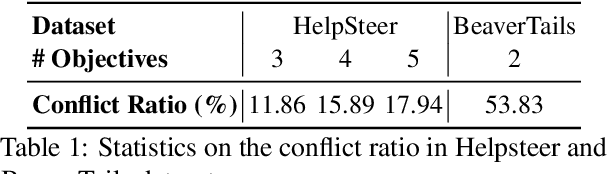
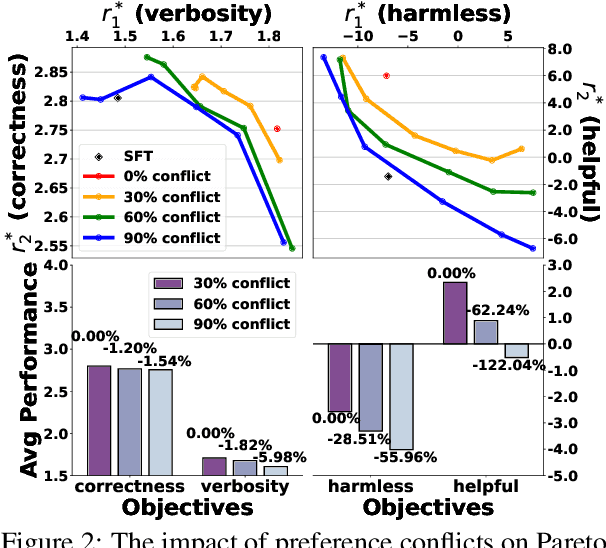

Multi-Objective Alignment (MOA) aims to align LLMs' responses with multiple human preference objectives, with Direct Preference Optimization (DPO) emerging as a prominent approach. However, we find that DPO-based MOA approaches suffer from widespread preference conflicts in the data, where different objectives favor different responses. This results in conflicting optimization directions, hindering the optimization on the Pareto Front. To address this, we propose to construct Pareto-optimal responses to resolve preference conflicts. To efficiently obtain and utilize such responses, we propose a self-improving DPO framework that enables LLMs to self-generate and select Pareto-optimal responses for self-supervised preference alignment. Extensive experiments on two datasets demonstrate the superior Pareto Front achieved by our framework compared to various baselines. Code is available at \url{https://github.com/zyttt-coder/SIPO}.