 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximin Learning of Individualized Treatment Effect on Multi-Domain Outcomes
Mar 28, 2026Precision mental health requires treatment decisions that account for heterogeneous symptoms reflecting multiple clinical domains. However, existing methods for estimating individualized treatment effects (ITE) rely on a single summary outcome or a specific set of observed symptoms or measures, which are sensitive to symptom selection and limit generalizability to unmeasured yet clinically relevant domains. We propose DRIFT, a new maximin framework for estimating robust ITEs from high-dimensional item-level data by leveraging latent factor representations and adversarial learning. DRIFT learns latent constructs via generalized factor analysis, then constructs an anchored on-target uncertainty set that extrapolates beyond the observed measures to approximate the broader hyper-population of potential outcomes. By optimizing worst-case performance over this uncertainty set, DRIFT yields ITEs that are robust to underrepresented or unmeasured domains. We further show that DRIFT is invariant to admissible reparameterizations of the latent factors and admits a closed-form maximin solution, with theoretical guarantees for identification and convergence. In analyses of a randomized controlled trial for major depressive disorder (EMBARC), DRIFT demonstrates superior performance and improved generalizability to external multi-domain outcomes, including side effects and self-reported symptoms not used during training.
Dynamic Classification of Latent Disease Progression with Auxiliary Surrogate Labels
Dec 11, 2024Disease progression prediction based on patients' evolving health information is challenging when true disease states are unknown due to diagnostic capabilities or high costs. For example, the absence of gold-standard neurological diagnoses hinders distinguishing Alzheimer's disease (AD) from related conditions such as AD-related dementias (ADRDs), including Lewy body dementia (LBD). Combining temporally dependent surrogate labels and health markers may improve disease prediction. However, existing literature models informative surrogate labels and observed variables that reflect the underlying states using purely generative approaches, limiting the ability to predict future states. We propose integrating the conventional hidden Markov model as a generative model with a time-varying discriminative classification model to simultaneously handle potentially misspecified surrogate labels and incorporate important markers of disease progression. We develop an adaptive forward-backward algorithm with subjective labels for estimation, and utilize the modified posterior and Viterbi algorithms to predict the progression of future states or new patients based on objective markers only. Importantly, the adaptation eliminates the need to model the marginal distribution of longitudinal markers, a requirement in traditional algorithms. Asymptotic properties are established, and significant improvement with finite samples is demonstrated via simulation studies. Analysis of the neuropathological dataset of the National Alzheimer's Coordinating Center (NACC) shows much improved accuracy in distinguishing LBD from AD.
Fusing Individualized Treatment Rules Using Secondary Outcomes
Feb 19, 2024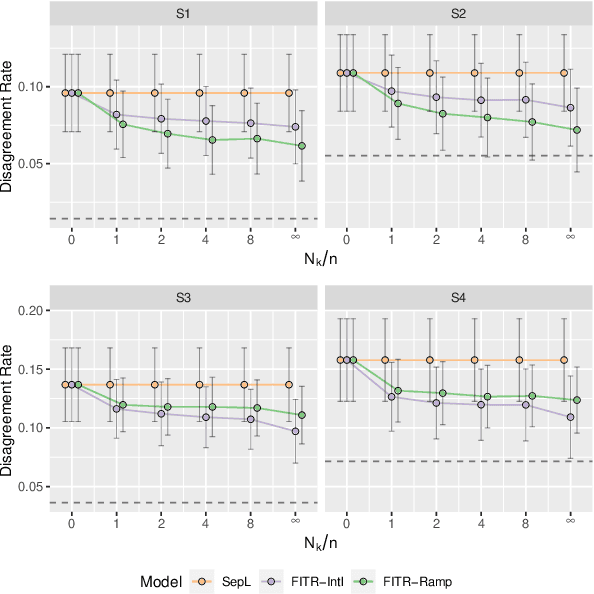
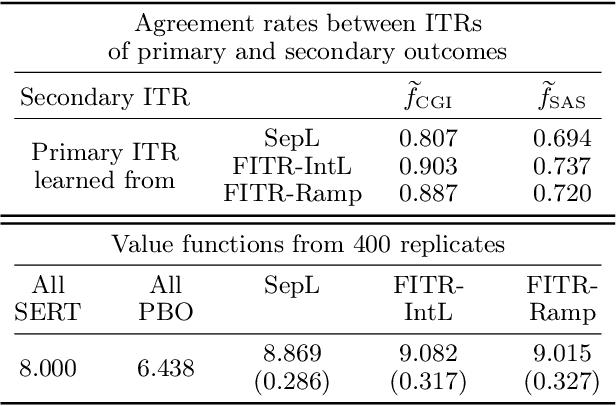
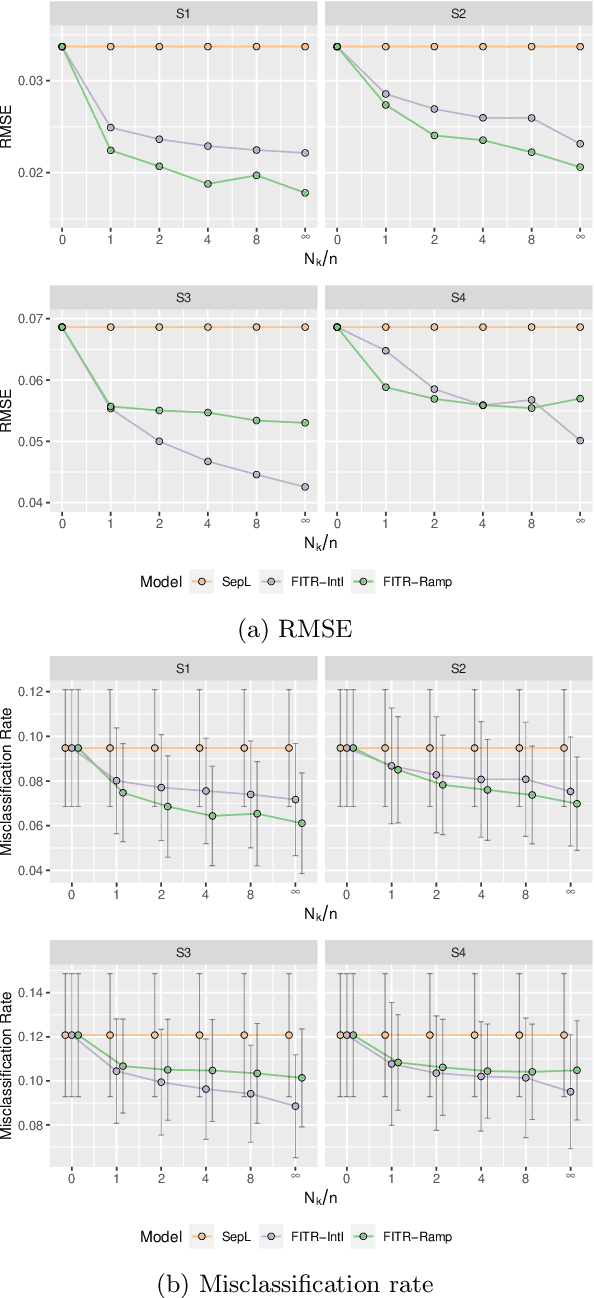

An individualized treatment rule (ITR) is a decision rule that recommends treatments for patients based on their individual feature variables. In many practices, the ideal ITR for the primary outcome is also expected to cause minimal harm to other secondary outcomes. Therefore, our objective is to learn an ITR that not only maximizes the value function for the primary outcome, but also approximates the optimal rule for the secondary outcomes as closely as possible. To achieve this goal, we introduce a fusion penalty to encourage the ITRs based on different outcomes to yield similar recommendations. Two algorithms are proposed to estimate the ITR using surrogate loss functions. We prove that the agreement rate between the estimated ITR of the primary outcome and the optimal ITRs of the secondary outcomes converges to the true agreement rate faster than if the secondary outcomes are not taken into consideration. Furthermore, we derive the non-asymptotic properties of the value function and misclassification rate for the proposed method. Finally, simulation studies and a real data example are used to demonstrate the finite-sample performance of the proposed method.
Reinforcement Learning with Hidden Markov Models for Discovering Decision-Making Dynamics
Jan 25, 2024



Major depressive disorder (MDD) presents challenges in diagnosis and treatment due to its complex and heterogeneous nature. Emerging evidence indicates that reward processing abnormalities may serve as a behavioral marker for MDD. To measure reward processing, patients perform computer-based behavioral tasks that involve making choices or responding to stimulants that are associated with different outcomes. Reinforcement learning (RL) models are fitted to extract parameters that measure various aspects of reward processing to characterize how patients make decisions in behavioral tasks. Recent findings suggest the inadequacy of characterizing reward learning solely based on a single RL model; instead, there may be a switching of decision-making processes between multiple strategies. An important scientific question is how the dynamics of learning strategies in decision-making affect the reward learning ability of individuals with MDD. Motivated by the probabilistic reward task (PRT) within the EMBARC study, we propose a novel RL-HMM framework for analyzing reward-based decision-making. Our model accommodates learning strategy switching between two distinct approaches under a hidden Markov model (HMM): subjects making decisions based on the RL model or opting for random choices. We account for continuous RL state space and allow time-varying transition probabilities in the HMM. We introduce a computationally efficient EM algorithm for parameter estimation and employ a nonparametric bootstrap for inference. We apply our approach to the EMBARC study to show that MDD patients are less engaged in RL compared to the healthy controls, and engagement is associated with brain activities in the negative affect circuitry during an emotional conflict task.
Representation Learning for Integrating Multi-domain Outcomes to Optimize Individualized Treatments
Oct 30, 2020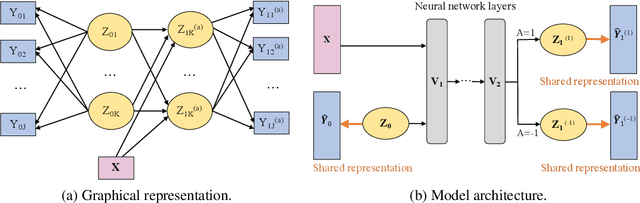
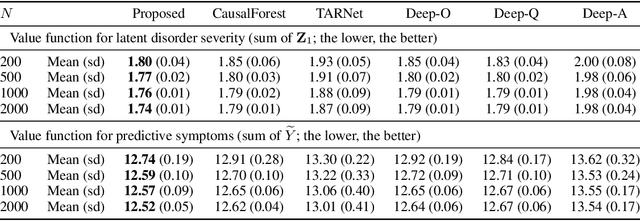
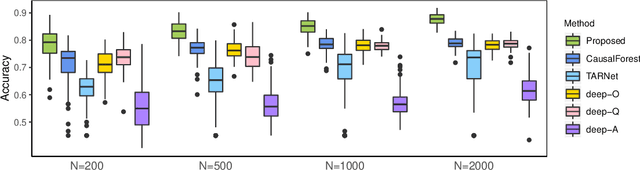

For mental disorders, patients' underlying mental states are non-observed latent constructs which have to be inferred from observed multi-domain measurements such as diagnostic symptoms and patient functioning scores. Additionally, substantial heterogeneity in the disease diagnosis between patients needs to be addressed for optimizing individualized treatment policy in order to achieve precision medicine. To address these challenges, we propose an integrated learning framework that can simultaneously learn patients' underlying mental states and recommend optimal treatments for each individual. This learning framework is based on the measurement theory in psychiatry for modeling multiple disease diagnostic measures as arising from the underlying causes (true mental states). It allows incorporation of the multivariate pre- and post-treatment outcomes as well as biological measures while preserving the invariant structure for representing patients' latent mental states. A multi-layer neural network is used to allow complex treatment effect heterogeneity. Optimal treatment policy can be inferred for future patients by comparing their potential mental states under different treatments given the observed multi-domain pre-treatment measurements. Experiments on simulated data and a real-world clinical trial data show that the learned treatment polices compare favorably to alternative methods on heterogeneous treatment effects, and have broad utilities which lead to better patient outcomes on multiple domains.