 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Edge Detection via Robust Collaborative Learning
Aug 27, 2023



Edge detection, as a core component in a wide range of visionoriented tasks, is to identify object boundaries and prominent edges in natural images. An edge detector is desired to be both efficient and accurate for practical use. To achieve the goal, two key issues should be concerned: 1) How to liberate deep edge models from inefficient pre-trained backbones that are leveraged by most existing deep learning methods, for saving the computational cost and cutting the model size; and 2) How to mitigate the negative influence from noisy or even wrong labels in training data, which widely exist in edge detection due to the subjectivity and ambiguity of annotators, for the robustness and accuracy. In this paper, we attempt to simultaneously address the above problems via developing a collaborative learning based model, termed PEdger. The principle behind our PEdger is that, the information learned from different training moments and heterogeneous (recurrent and non recurrent in this work) architectures, can be assembled to explore robust knowledge against noisy annotations, even without the help of pre-training on extra data. Extensive ablation studies together with quantitative and qualitative experimental comparisons on the BSDS500 and NYUD datasets are conducted to verify the effectiveness of our design, and demonstrate its superiority over other competitors in terms of accuracy, speed, and model size. Codes can be found at https://github.co/ForawardStar/PEdger.
EDIT: Exemplar-Domain Aware Image-to-Image Translation
Nov 24, 2019

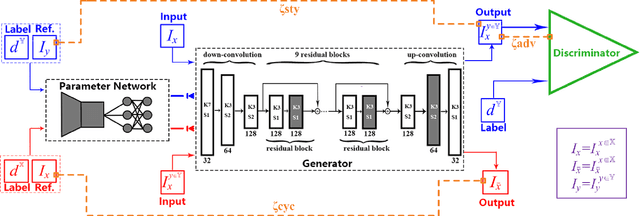

Image-to-image translation is to convert an image of the certain style to another of the target style with the content preserved. A desired translator should be capable to generate diverse results in a controllable (many-to-many) fashion. To this end, we design a novel generative adversarial network, namely exemplar-domain aware image-to-image translator (EDIT for short). The principle behind is that, for images from multiple domains, the content features can be obtained by a uniform extractor, while (re-)stylization is achieved by mapping the extracted features specifically to different purposes (domains and exemplars). The generator of our EDIT comprises of a part of blocks configured by shared parameters, and the rest by varied parameters exported by an exemplar-domain aware parameter network. In addition, a discriminator is equipped during the training phase to guarantee the output satisfying the distribution of the target domain. Our EDIT can flexibly and effectively work on multiple domains and arbitrary exemplars in a unified neat model. We conduct experiments to show the efficacy of our design, and reveal its advances over other state-of-the-art methods both quantitatively and qualitatively.