 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-VLGM : Bi-Level Class-Severity-Aware Vision-Language Graph Matching for Text Guided Medical Image Segmentation
May 20, 2023Medical reports with substantial information can be naturally complementary to medical images for computer vision tasks, and the modality gap between vision and language can be solved by vision-language matching (VLM). However, current vision-language models distort the intra-model relation and mainly include class information in prompt learning that is insufficient for segmentation task. In this paper, we introduce a Bi-level class-severity-aware Vision-Language Graph Matching (Bi-VLGM) for text guided medical image segmentation, composed of a word-level VLGM module and a sentence-level VLGM module, to exploit the class-severity-aware relation among visual-textual features. In word-level VLGM, to mitigate the distorted intra-modal relation during VLM, we reformulate VLM as graph matching problem and introduce a vision-language graph matching (VLGM) to exploit the high-order relation among visual-textual features. Then, we perform VLGM between the local features for each class region and class-aware prompts to bridge their gap. In sentence-level VLGM, to provide disease severity information for segmentation task, we introduce a severity-aware prompting to quantify the severity level of retinal lesion, and perform VLGM between the global features and the severity-aware prompts. By exploiting the relation between the local (global) and class (severity) features, the segmentation model can selectively learn the class-aware and severity-aware information to promote performance. Extensive experiments prove the effectiveness of our method and its superiority to existing methods. Source code is to be released.
Ground-aware Monocular 3D Object Detection for Autonomous Driving
Feb 01, 2021

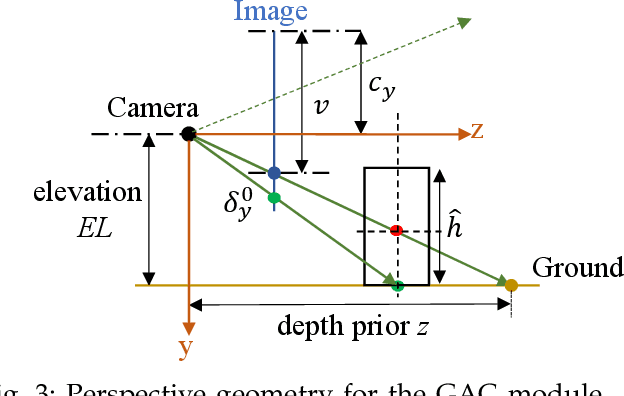
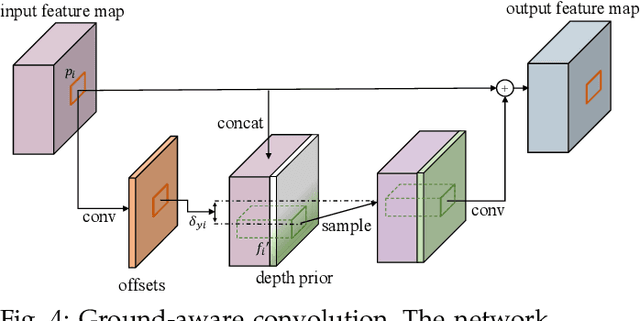
Estimating the 3D position and orientation of objects in the environment with a single RGB camera is a critical and challenging task for low-cost urban autonomous driving and mobile robots. Most of the existing algorithms are based on the geometric constraints in 2D-3D correspondence, which stems from generic 6D object pose estimation. We first identify how the ground plane provides additional clues in depth reasoning in 3D detection in driving scenes. Based on this observation, we then improve the processing of 3D anchors and introduce a novel neural network module to fully utilize such application-specific priors in the framework of deep learning. Finally, we introduce an efficient neural network embedded with the proposed module for 3D object detection. We further verify the power of the proposed module with a neural network designed for monocular depth prediction. The two proposed networks achieve state-of-the-art performances on the KITTI 3D object detection and depth prediction benchmarks, respectively. The code will be published in https://www.github.com/Owen-Liuyuxuan/visualDet3D