 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperEdge: Towards a Generalization Model for Self-Supervised Edge Detection
Jan 04, 2024
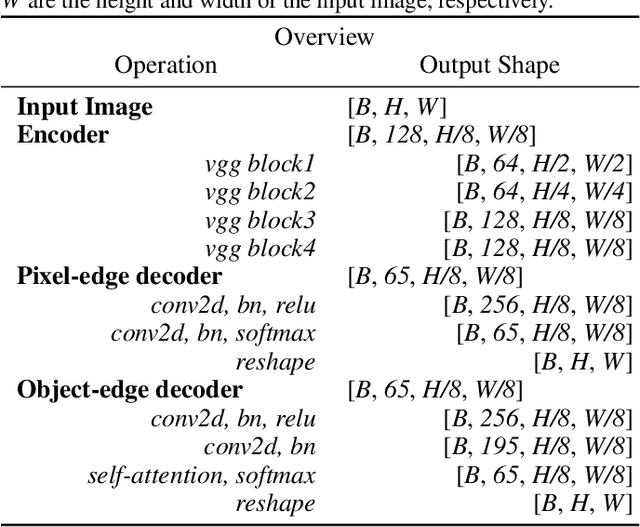
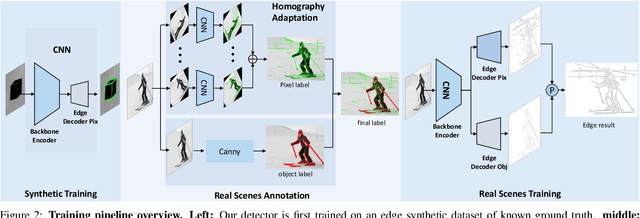
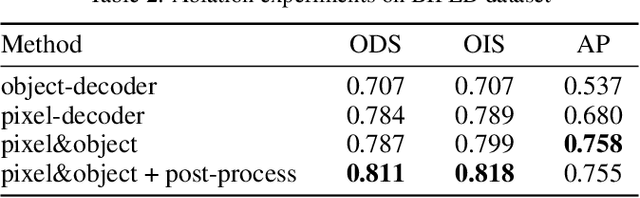
Edge detection is a fundamental technique in various computer vision tasks. Edges are indeed effectively delineated by pixel discontinuity and can offer reliable structural information even in textureless areas. State-of-the-art heavily relies on pixel-wise annotations, which are labor-intensive and subject to inconsistencies when acquired manually. In this work, we propose a novel self-supervised approach for edge detection that employs a multi-level, multi-homography technique to transfer annotations from synthetic to real-world datasets. To fully leverage the generated edge annotations, we developed SuperEdge, a streamlined yet efficient model capable of concurrently extracting edges at pixel-level and object-level granularity. Thanks to self-supervised training, our method eliminates the dependency on manual annotated edge labels, thereby enhancing its generalizability across diverse datasets. Comparative evaluations reveal that SuperEdge advances edge detection, demonstrating improvements of 4.9% in ODS and 3.3% in OIS over the existing STEdge method on BIPEDv2.
Bi-VLGM : Bi-Level Class-Severity-Aware Vision-Language Graph Matching for Text Guided Medical Image Segmentation
May 20, 2023Medical reports with substantial information can be naturally complementary to medical images for computer vision tasks, and the modality gap between vision and language can be solved by vision-language matching (VLM). However, current vision-language models distort the intra-model relation and mainly include class information in prompt learning that is insufficient for segmentation task. In this paper, we introduce a Bi-level class-severity-aware Vision-Language Graph Matching (Bi-VLGM) for text guided medical image segmentation, composed of a word-level VLGM module and a sentence-level VLGM module, to exploit the class-severity-aware relation among visual-textual features. In word-level VLGM, to mitigate the distorted intra-modal relation during VLM, we reformulate VLM as graph matching problem and introduce a vision-language graph matching (VLGM) to exploit the high-order relation among visual-textual features. Then, we perform VLGM between the local features for each class region and class-aware prompts to bridge their gap. In sentence-level VLGM, to provide disease severity information for segmentation task, we introduce a severity-aware prompting to quantify the severity level of retinal lesion, and perform VLGM between the global features and the severity-aware prompts. By exploiting the relation between the local (global) and class (severity) features, the segmentation model can selectively learn the class-aware and severity-aware information to promote performance. Extensive experiments prove the effectiveness of our method and its superiority to existing methods. Source code is to be released.