 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Dimension Dependence for Bandit Convex Optimization with Gradient Variations
Feb 04, 2026Gradient-variation online learning has drawn increasing attention due to its deep connections to game theory, optimization, etc. It has been studied extensively in the full-information setting, but is underexplored with bandit feedback. In this work, we focus on gradient variation in Bandit Convex Optimization (BCO) with two-point feedback. By proposing a refined analysis on the non-consecutive gradient variation, a fundamental quantity in gradient variation with bandits, we improve the dimension dependence for both convex and strongly convex functions compared with the best known results (Chiang et al., 2013). Our improved analysis for the non-consecutive gradient variation also implies other favorable problem-dependent guarantees, such as gradient-variance and small-loss regrets. Beyond the two-point setup, we demonstrate the versatility of our technique by achieving the first gradient-variation bound for one-point bandit linear optimization over hyper-rectangular domains. Finally, we validate the effectiveness of our results in more challenging tasks such as dynamic/universal regret minimization and bandit games, establishing the first gradient-variation dynamic and universal regret bounds for two-point BCO and fast convergence rates in bandit games.
Optimistic Online-to-Batch Conversions for Accelerated Convergence and Universality
Nov 10, 2025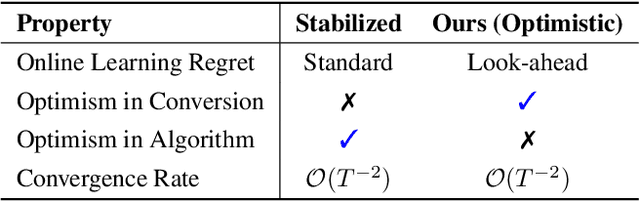
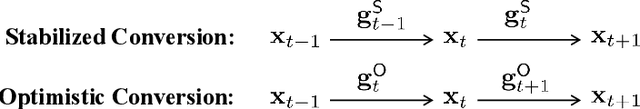
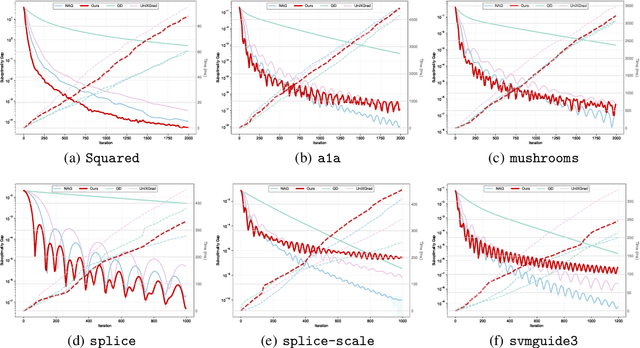
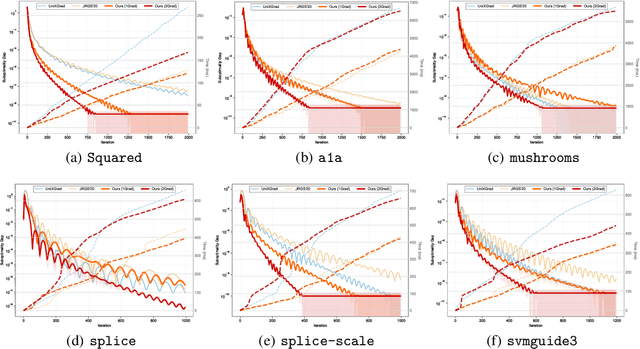
In this work, we study offline convex optimization with smooth objectives, where the classical Nesterov's Accelerated Gradient (NAG) method achieves the optimal accelerated convergence. Extensive research has aimed to understand NAG from various perspectives, and a recent line of work approaches this from the viewpoint of online learning and online-to-batch conversion, emphasizing the role of optimistic online algorithms for acceleration. In this work, we contribute to this perspective by proposing novel optimistic online-to-batch conversions that incorporate optimism theoretically into the analysis, thereby significantly simplifying the online algorithm design while preserving the optimal convergence rates. Specifically, we demonstrate the effectiveness of our conversions through the following results: (i) when combined with simple online gradient descent, our optimistic conversion achieves the optimal accelerated convergence; (ii) our conversion also applies to strongly convex objectives, and by leveraging both optimistic online-to-batch conversion and optimistic online algorithms, we achieve the optimal accelerated convergence rate for strongly convex and smooth objectives, for the first time through the lens of online-to-batch conversion; (iii) our optimistic conversion can achieve universality to smoothness -- applicable to both smooth and non-smooth objectives without requiring knowledge of the smoothness coefficient -- and remains efficient as non-universal methods by using only one gradient query in each iteration. Finally, we highlight the effectiveness of our optimistic online-to-batch conversions by a precise correspondence with NAG.
Universal Online Learning with Gradual Variations: A Multi-layer Online Ensemble Approach
Jul 17, 2023In this paper, we propose an online convex optimization method with two different levels of adaptivity. On a higher level, our method is agnostic to the specific type and curvature of the loss functions, while at a lower level, it can exploit the niceness of the environments and attain problem-dependent guarantees. To be specific, we obtain $\mathcal{O}(\ln V_T)$, $\mathcal{O}(d \ln V_T)$ and $\hat{\mathcal{O}}(\sqrt{V_T})$ regret bounds for strongly convex, exp-concave and convex loss functions, respectively, where $d$ is the dimension, $V_T$ denotes problem-dependent gradient variations and $\hat{\mathcal{O}}(\cdot)$-notation omits logarithmic factors on $V_T$. Our result finds broad implications and applications. It not only safeguards the worst-case guarantees, but also implies the small-loss bounds in analysis directly. Besides, it draws deep connections with adversarial/stochastic convex optimization and game theory, further validating its practical potential. Our method is based on a multi-layer online ensemble incorporating novel ingredients, including carefully-designed optimism for unifying diverse function types and cascaded corrections for algorithmic stability. Remarkably, despite its multi-layer structure, our algorithm necessitates only one gradient query per round, making it favorable when the gradient evaluation is time-consuming. This is facilitated by a novel regret decomposition equipped with customized surrogate losses.
Storage Fit Learning with Feature Evolvable Streams
Jul 22, 2020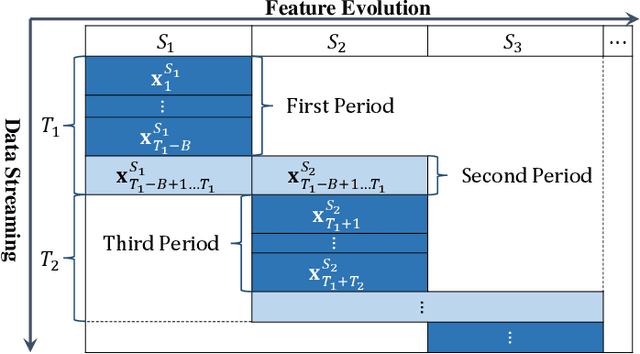
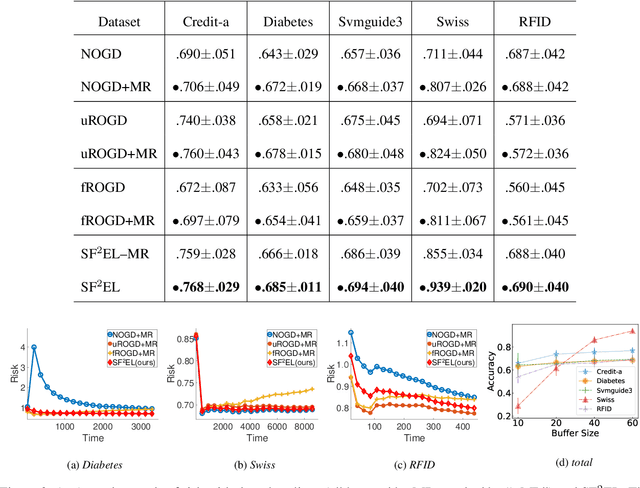
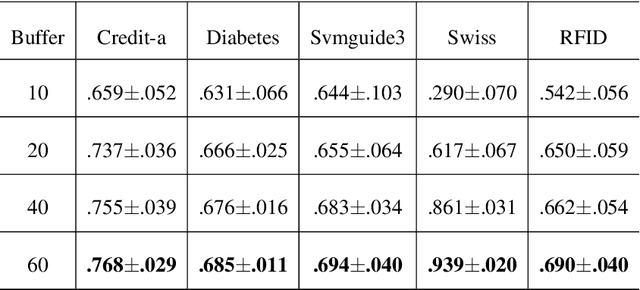
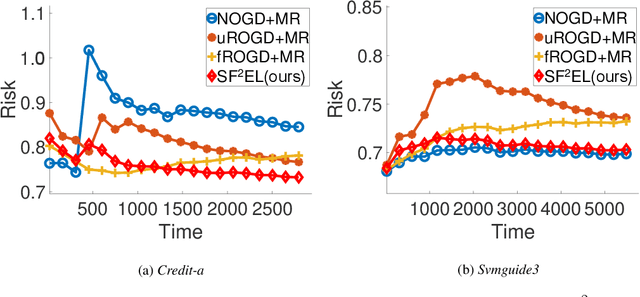
Feature evolvable learning has been widely studied in recent years where old features will vanish and new features will emerge when learning with streams. Conventional methods usually assume that a label will be revealed after prediction at each time step. However, in practice, this assumption may not hold whereas no label will be given at most time steps. To tackle this problem, we leverage the technique of manifold regularization to utilize the previous similar data to assist the refinement of the online model. Nevertheless, this approach needs to store all previous data which is impossible in learning with streams that arrive sequentially in large volume. Thus we need a buffer to store part of them. Considering that different devices may have different storage budgets, the learning approaches should be flexible subject to the storage budget limit. In this paper, we propose a new setting: Storage-Fit Feature-Evolvable streaming Learning (SF2EL) which incorporates the issue of rarely-provided labels into feature evolution. Our framework is able to fit its behavior to different storage budgets when learning with feature evolvable streams with unlabeled data. Besides, both theoretical and empirical results validate that our approach can preserve the merit of the original feature evolvable learning i.e., can always track the best baseline and thus perform well at any time step.