 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional neural network models for cancer type prediction based on gene expression
Jun 18, 2019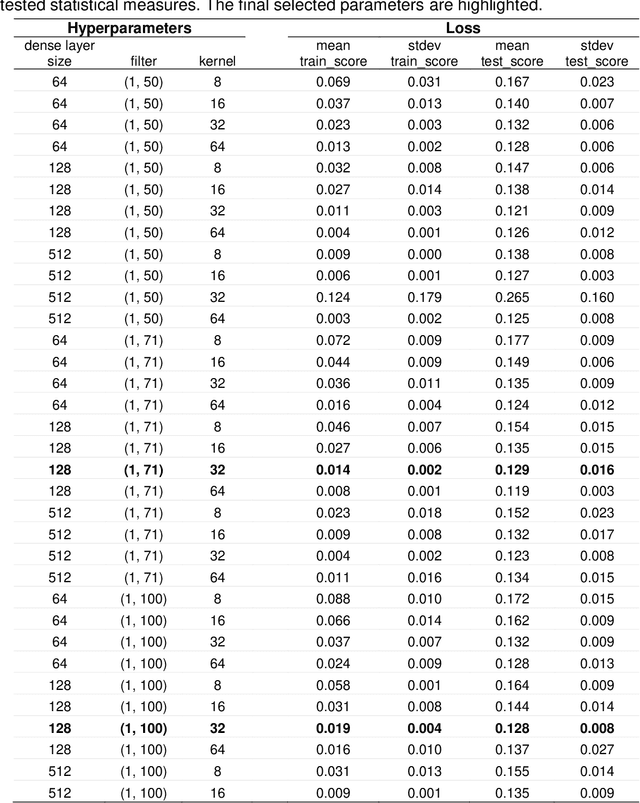
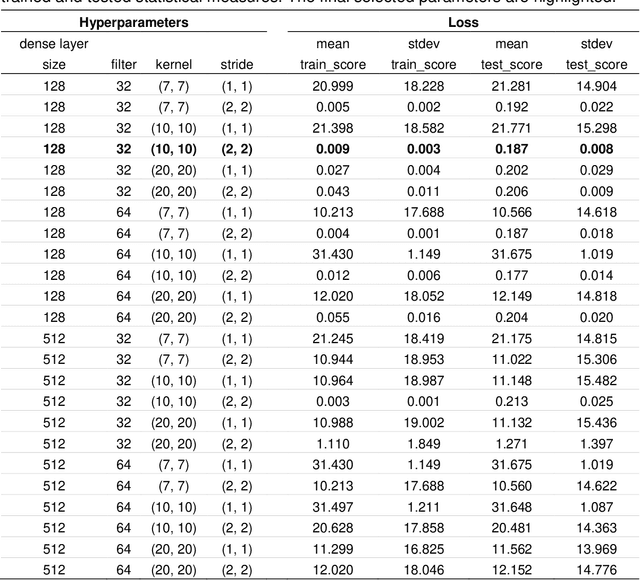
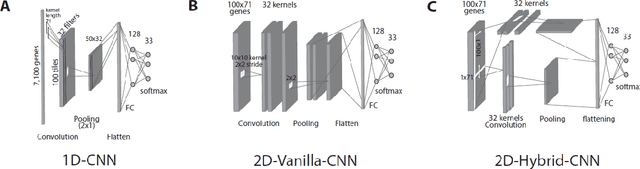
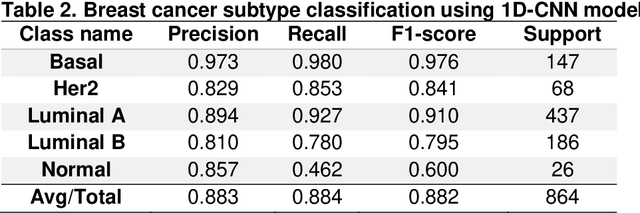
Background Precise prediction of cancer types is vital for cancer diagnosis and therapy. Important cancer marker genes can be inferred through predictive model. Several studies have attempted to build machine learning models for this task however none has taken into consideration the effects of tissue of origin that can potentially bias the identification of cancer markers. Results In this paper, we introduced several Convolutional Neural Network (CNN) models that take unstructured gene expression inputs to classify tumor and non-tumor samples into their designated cancer types or as normal. Based on different designs of gene embeddings and convolution schemes, we implemented three CNN models: 1D-CNN, 2D-Vanilla-CNN, and 2D-Hybrid-CNN. The models were trained and tested on combined 10,340 samples of 33 cancer types and 731 matched normal tissues of The Cancer Genome Atlas (TCGA). Our models achieved excellent prediction accuracies (93.9-95.0%) among 34 classes (33 cancers and normal). Furthermore, we interpreted one of the models, known as 1D-CNN model, with a guided saliency technique and identified a total of 2,090 cancer markers (108 per class). The concordance of differential expression of these markers between the cancer type they represent and others is confirmed. In breast cancer, for instance, our model identified well-known markers, such as GATA3 and ESR1. Finally, we extended the 1D-CNN model for prediction of breast cancer subtypes and achieved an average accuracy of 88.42% among 5 subtypes. The codes can be found at https://github.com/chenlabgccri/CancerTypePrediction.
GSAE: an autoencoder with embedded gene-set nodes for genomics functional characterization
May 21, 2018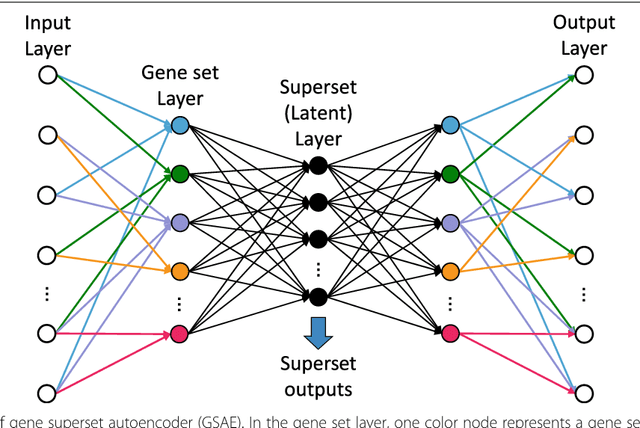
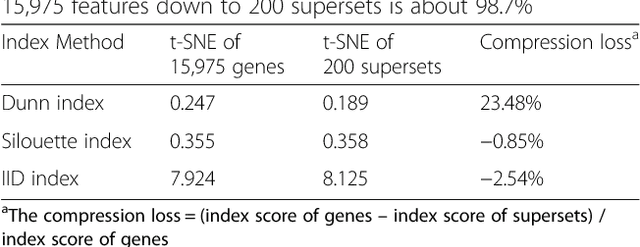
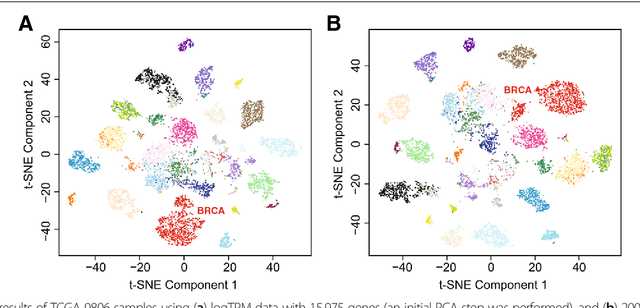
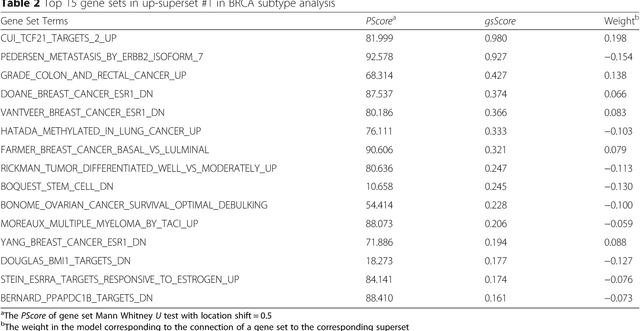
Bioinformatics tools have been developed to interpret gene expression data at the gene set level, and these gene set based analyses improve the biologists' capability to discover functional relevance of their experiment design. While elucidating gene set individually, inter gene sets association is rarely taken into consideration. Deep learning, an emerging machine learning technique in computational biology, can be used to generate an unbiased combination of gene set, and to determine the biological relevance and analysis consistency of these combining gene sets by leveraging large genomic data sets. In this study, we proposed a gene superset autoencoder (GSAE), a multi-layer autoencoder model with the incorporation of a priori defined gene sets that retain the crucial biological features in the latent layer. We introduced the concept of the gene superset, an unbiased combination of gene sets with weights trained by the autoencoder, where each node in the latent layer is a superset. Trained with genomic data from TCGA and evaluated with their accompanying clinical parameters, we showed gene supersets' ability of discriminating tumor subtypes and their prognostic capability. We further demonstrated the biological relevance of the top component gene sets in the significant supersets. Using autoencoder model and gene superset at its latent layer, we demonstrated that gene supersets retain sufficient biological information with respect to tumor subtypes and clinical prognostic significance. Superset also provides high reproducibility on survival analysis and accurate prediction for cancer subtypes.
Predicting drug response of tumors from integrated genomic profiles by deep neural networks
May 20, 2018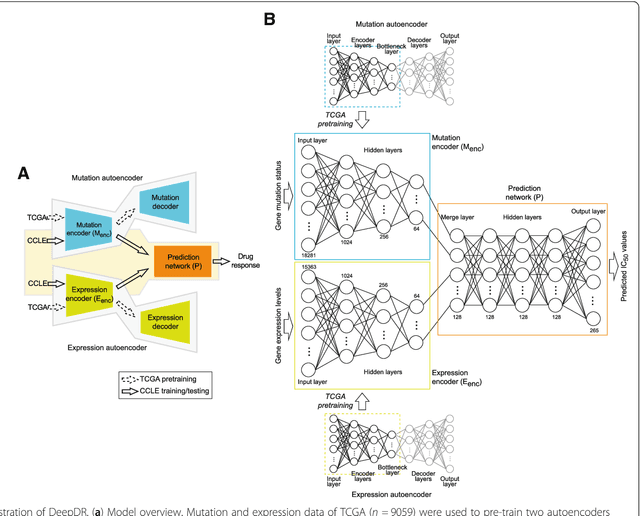


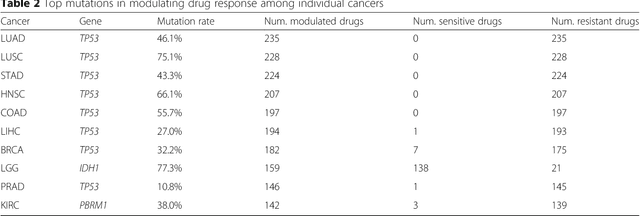
The study of high-throughput genomic profiles from a pharmacogenomics viewpoint has provided unprecedented insights into the oncogenic features modulating drug response. A recent screening of ~1,000 cancer cell lines to a collection of anti-cancer drugs illuminated the link between genotypes and vulnerability. However, due to essential differences between cell lines and tumors, the translation into predicting drug response in tumors remains challenging. Here we proposed a DNN model to predict drug response based on mutation and expression profiles of a cancer cell or a tumor. The model contains a mutation and an expression encoders pre-trained using a large pan-cancer dataset to abstract core representations of high-dimension data, followed by a drug response predictor network. Given a pair of mutation and expression profiles, the model predicts IC50 values of 265 drugs. We trained and tested the model on a dataset of 622 cancer cell lines and achieved an overall prediction performance of mean squared error at 1.96 (log-scale IC50 values). The performance was superior in prediction error or stability than two classical methods and four analog DNNs of our model. We then applied the model to predict drug response of 9,059 tumors of 33 cancer types. The model predicted both known, including EGFR inhibitors in non-small cell lung cancer and tamoxifen in ER+ breast cancer, and novel drug targets. The comprehensive analysis further revealed the molecular mechanisms underlying the resistance to a chemotherapeutic drug docetaxel in a pan-cancer setting and the anti-cancer potential of a novel agent, CX-5461, in treating gliomas and hematopoietic malignancies. Overall, our model and findings improve the prediction of drug response and the identification of novel therapeutic options.