 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Altruistic and Fairness Preference Induces Advanced Mutual Cooperation in Sequential Social Dilemmas
Jul 06, 2026Inducing cooperation among distributed agents is still a difficult problem in the field of multi-agent reinforcement learning (MARL), particularly in social dilemma situations. There, individual interests are misaligned with the common good and individual rationality leads to suboptimal group outcomes. In contrast, humans are able to achieve cooperation with one another in such situations. A common explanation for such cooperative behavior is that individuals have social preferences. In order to achieve cooperation in MARL, we design a new utility function integrating altruistic preferences (incentive for other's reward) and fairness preferences (incentive for equality) from social psychology and behavioral economics, namely, Altruistic and Fairness Preference (AFP), a reward-sharing mechanism which converts one's own and other's rewards to incentives for cooperative behavior. We performed comparative experiments with standard RL and inequity aversion agents in two challenging sequential social dilemma games, and showed that AFP agents successfully achieved mutual cooperation with more collective rewards and higher equity than the baselines. To further understand the progression of AFP during training, we subsequently explore the effects of altruistic preferences and fairness preferences on agents' behavior. The results suggest that altruistic preferences encourage agents to contribute to the public goods, and fairness preferences induce mutual behavior between agents.
Better Understanding, Understanding Better
Jun 30, 2026"Any fool can know; the point is to understand." A well-known remark often attributed to Einstein captures a widely shared intuition: understanding is more than merely knowing. Yet epistemic logic has paid relatively little attention to understanding, despite its central role in contemporary epistemology, philosophy of science, and recent debates about AI. A recurring theme in the philosophical literature is that, unlike knowledge, understanding comes in degrees: one may understand something more or less well, and one's understanding may be better than another's. We introduce a comparative epistemic logic of understanding with level-indexed understanding modalities and a comparative connective for saying that one agent understands why a proposition better than another agent does. Semantically, we enrich multi-agent epistemic models with agent-indexed graded explanation structures and a justification-style term algebra. This yields a unified framework for representing minimal, ordinary, more demanding, and ideal understanding, together with comparisons between agents with respect to the same formula at issue. We distinguish a finitary bounded-level calculus from an infinitary full-language companion system. We establish soundness and strong completeness, and show that each fixed finite-level fragment is decidable.
* In Proceedings AiML 2026, arXiv:2606.29444
Let's Ask Gauss: Improved One-Run Privacy Auditing
Jun 10, 2026Privacy auditing provides an important safeguard by estimating the actual information leaked by a model, thus ensuring that theoretical privacy guarantees hold in practice. We study empirical privacy auditing for differentially private (DP) machine learning, focusing on efficient one-run methods for mechanisms such as DP-SGD. Prior one-run approaches threshold training examples or "canaries" into binary membership guesses, which discards useful information. We show that, in the white-box DP-SGD setting, canary-aligned signals naturally form a sequence of random variables whose normalized sum is asymptotically Gaussian. Leveraging this distributional perspective, we develop a DP-auditing framework that leads to tighter privacy lower bounds from a single training run.
Thousand-GPU Large-Scale Training and Optimization Recipe for AI-Native Cloud Embodied Intelligence Infrastructure
Mar 11, 2026Embodied intelligence is a key step towards Artificial General Intelligence (AGI), yet its development faces multiple challenges including data, frameworks, infrastructure, and evaluation systems. To address these issues, we have, for the first time in the industry, launched a cloud-based, thousand-GPU distributed training platform for embodied intelligence, built upon the widely adopted LeRobot framework, and have systematically overcome bottlenecks across the entire pipeline. At the data layer, we have restructured the data pipeline to optimize the flow of embodied training data. In terms of training, for the GR00T-N1.5 model, utilizing thousand-GPU clusters and data at the scale of hundreds of millions, the single-round training time has been reduced from 15 hours to just 22 minutes, achieving a 40-fold speedup. At the model layer, by combining variable-length FlashAttention and Data Packing, we have moved from sample redundancy to sequence integration, resulting in a 188% speed increase; π-0.5 attention optimization has accelerated training by 165%; and FP8 quantization has delivered a 140% speedup. On the infrastructure side, relying on high-performance storage, a 3.2T RDMA network, and a Ray-driven elastic AI data lake, we have achieved deep synergy among data, storage, communication, and computation. We have also built an end-to-end evaluation system, creating a closed loop from training to simulation to assessment. This framework has already been fully validated on thousand-GPU clusters, laying a crucial technical foundation for the development and application of next-generation autonomous intelligent robots, and is expected to accelerate the arrival of the era of human-machine integration.
Sequential Auditing for f-Differential Privacy
Feb 06, 2026We present new auditors to assess Differential Privacy (DP) of an algorithm based on output samples. Such empirical auditors are common to check for algorithmic correctness and implementation bugs. Most existing auditors are batch-based or targeted toward the traditional notion of $(\varepsilon,δ)$-DP; typically both. In this work, we shift the focus to the highly expressive privacy concept of $f$-DP, in which the entire privacy behavior is captured by a single tradeoff curve. Our auditors detect violations across the full privacy spectrum with statistical significance guarantees, which are supported by theory and simulations. Most importantly, and in contrast to prior work, our auditors do not require a user-specified sample size as an input. Rather, they adaptively determine a near-optimal number of samples needed to reach a decision, thereby avoiding the excessively large sample sizes common in many auditing studies. This reduction in sampling cost becomes especially beneficial for expensive training procedures such as DP-SGD. Our method supports both whitebox and blackbox settings and can also be executed in single-run frameworks.
LingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
Privacy-Utility Tradeoff of OLS with Random Projections
Sep 03, 2023
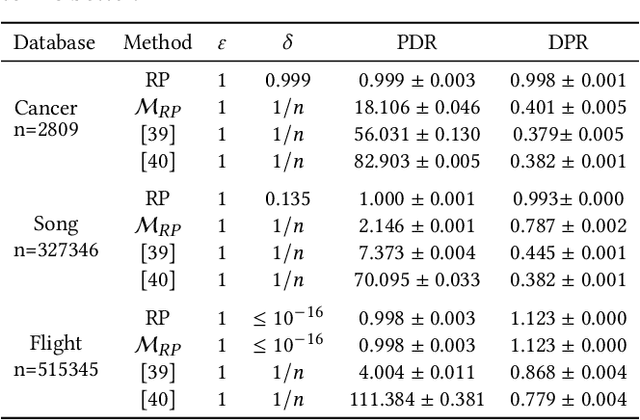

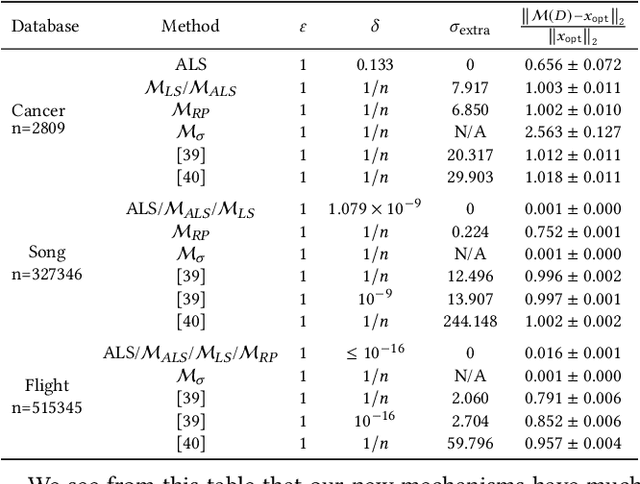
We study the differential privacy (DP) of a core ML problem, linear ordinary least squares (OLS), a.k.a. $\ell_2$-regression. Our key result is that the approximate LS algorithm (ALS) (Sarlos, 2006), a randomized solution to the OLS problem primarily used to improve performance on large datasets, also preserves privacy. ALS achieves a better privacy/utility tradeoff, without modifications or further noising, when compared to alternative private OLS algorithms which modify and/or noise OLS. We give the first {\em tight} DP-analysis for the ALS algorithm and the standard Gaussian mechanism (Dwork et al., 2014) applied to OLS. Our methodology directly improves the privacy analysis of (Blocki et al., 2012) and (Sheffet, 2019)) and introduces new tools which may be of independent interest: (1) the exact spectrum of $(\epsilon, \delta)$-DP parameters (``DP spectrum") for mechanisms whose output is a $d$-dimensional Gaussian, and (2) an improved DP spectrum for random projection (compared to (Blocki et al., 2012) and (Sheffet, 2019)). All methods for private OLS (including ours) assume, often implicitly, restrictions on the input database, such as bounds on leverage and residuals. We prove that such restrictions are necessary. Hence, computing the privacy of mechanisms such as ALS must estimate these database parameters, which can be infeasible in big datasets. For more complex ML models, DP bounds may not even be tractable. There is a need for blackbox DP-estimators (Lu et al., 2022) which empirically estimate a data-dependent privacy. We demonstrate the effectiveness of such a DP-estimator by empirically recovering a DP-spectrum that matches our theory for OLS. This validates the DP-estimator in a nontrivial ML application, opening the door to its use in more complex nonlinear ML settings where theory is unavailable.
A Comparison of First-order Algorithms for Machine Learning
Apr 26, 2014
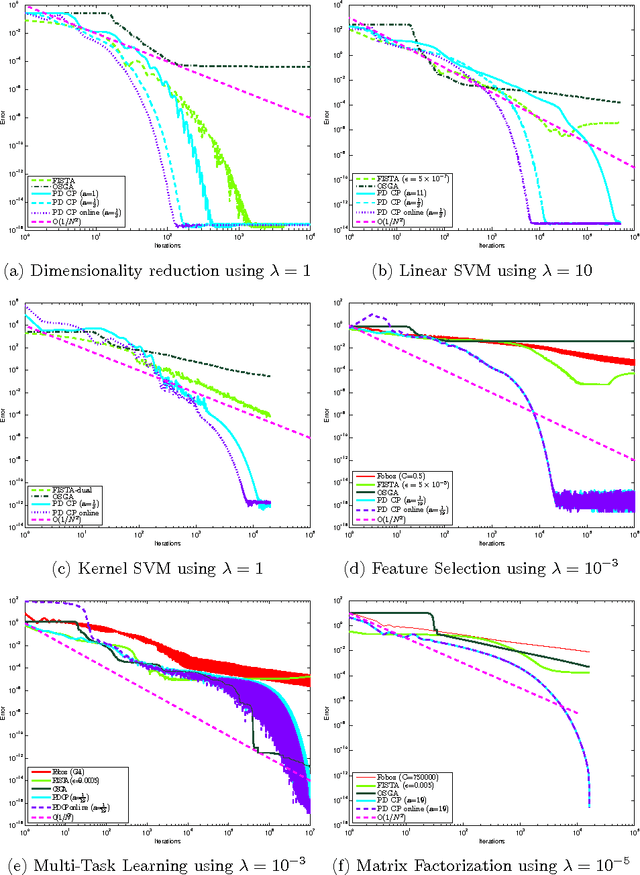

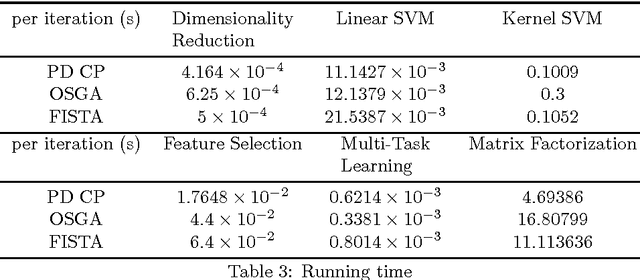
Using an optimization algorithm to solve a machine learning problem is one of mainstreams in the field of science. In this work, we demonstrate a comprehensive comparison of some state-of-the-art first-order optimization algorithms for convex optimization problems in machine learning. We concentrate on several smooth and non-smooth machine learning problems with a loss function plus a regularizer. The overall experimental results show the superiority of primal-dual algorithms in solving a machine learning problem from the perspectives of the ease to construct, running time and accuracy.