 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentralized Feature Pyramid for Object Detection
Oct 05, 2022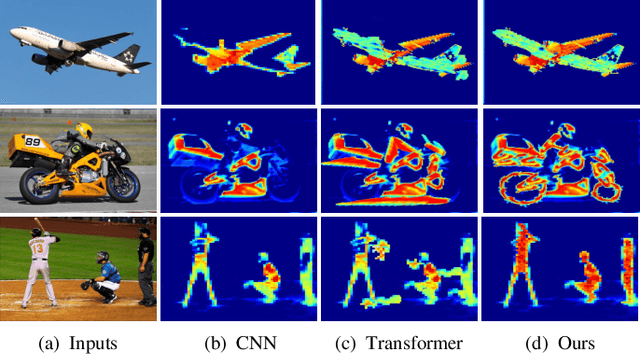


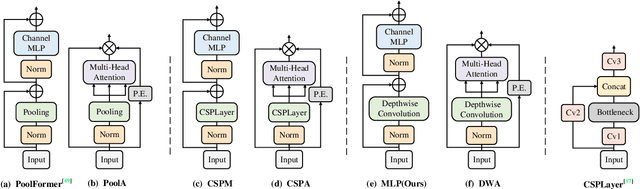
Visual feature pyramid has shown its superiority in both effectiveness and efficiency in a wide range of applications. However, the existing methods exorbitantly concentrate on the inter-layer feature interactions but ignore the intra-layer feature regulations, which are empirically proved beneficial. Although some methods try to learn a compact intra-layer feature representation with the help of the attention mechanism or the vision transformer, they ignore the neglected corner regions that are important for dense prediction tasks. To address this problem, in this paper, we propose a Centralized Feature Pyramid (CFP) for object detection, which is based on a globally explicit centralized feature regulation. Specifically, we first propose a spatial explicit visual center scheme, where a lightweight MLP is used to capture the globally long-range dependencies and a parallel learnable visual center mechanism is used to capture the local corner regions of the input images. Based on this, we then propose a globally centralized regulation for the commonly-used feature pyramid in a top-down fashion, where the explicit visual center information obtained from the deepest intra-layer feature is used to regulate frontal shallow features. Compared to the existing feature pyramids, CFP not only has the ability to capture the global long-range dependencies, but also efficiently obtain an all-round yet discriminative feature representation. Experimental results on the challenging MS-COCO validate that our proposed CFP can achieve the consistent performance gains on the state-of-the-art YOLOv5 and YOLOX object detection baselines.