 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparation capacity of linear reservoirs with random connectivity matrix
May 01, 2024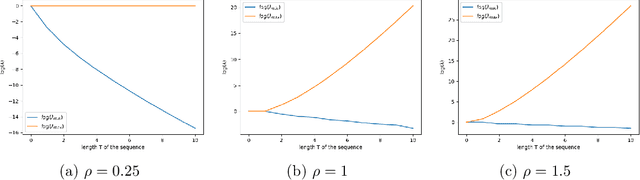
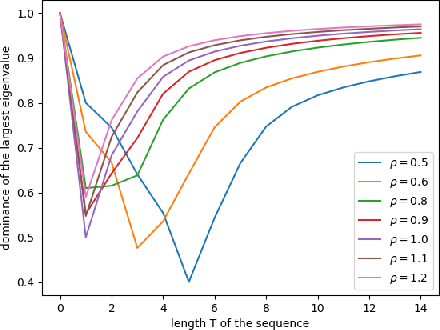
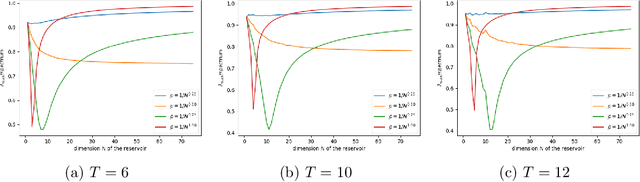
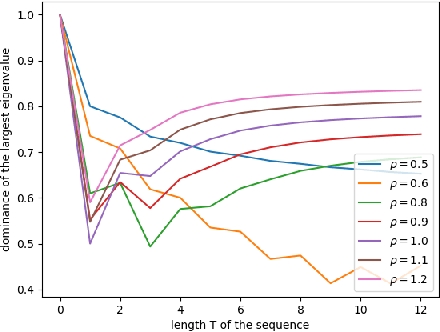
We argue that the success of reservoir computing lies within the separation capacity of the reservoirs and show that the expected separation capacity of random linear reservoirs is fully characterised by the spectral decomposition of an associated generalised matrix of moments. Of particular interest are reservoirs with Gaussian matrices that are either symmetric or whose entries are all independent. In the symmetric case, we prove that the separation capacity always deteriorates with time; while for short inputs, separation with large reservoirs is best achieved when the entries of the matrix are scaled with a factor $\rho_T/\sqrt{N}$, where $N$ is the dimension of the reservoir and $\rho_T$ depends on the maximum length of the input time series. In the i.i.d. case, we establish that optimal separation with large reservoirs is consistently achieved when the entries of the reservoir matrix are scaled with the exact factor $1/\sqrt{N}$. We further give upper bounds on the quality of separation in function of the length of the time series. We complement this analysis with an investigation of the likelihood of this separation and the impact of the chosen architecture on separation consistency.
Path classification by stochastic linear recurrent neural networks
Aug 06, 2021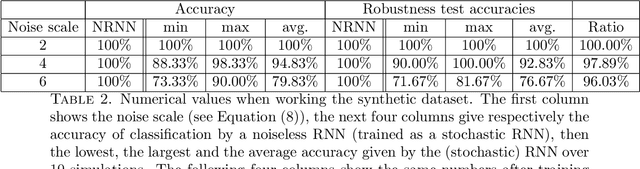
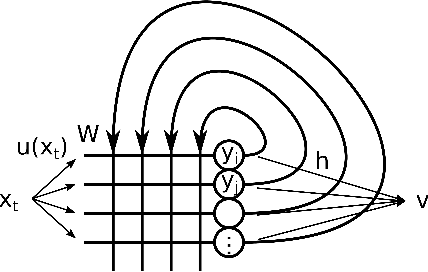
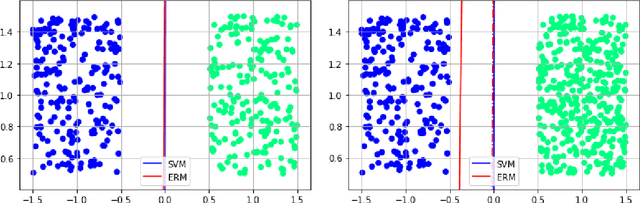
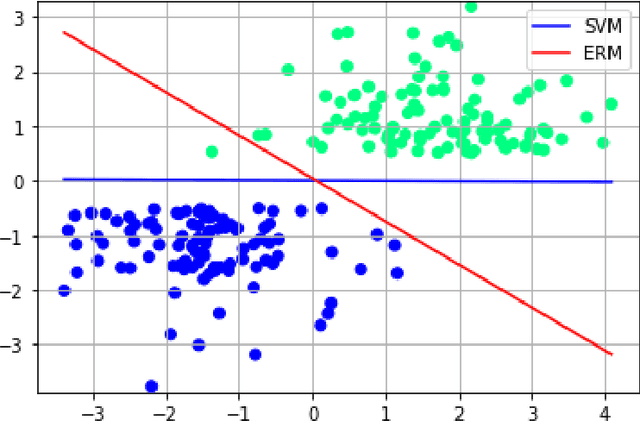
We investigate the functioning of a classifying biological neural network from the perspective of statistical learning theory, modelled, in a simplified setting, as a continuous-time stochastic recurrent neural network (RNN) with identity activation function. In the purely stochastic (robust) regime, we give a generalisation error bound that holds with high probability, thus showing that the empirical risk minimiser is the best-in-class hypothesis. We show that RNNs retain a partial signature of the paths they are fed as the unique information exploited for training and classification tasks. We argue that these RNNs are easy to train and robust and back these observations with numerical experiments on both synthetic and real data. We also exhibit a trade-off phenomenon between accuracy and robustness.