 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Demand Uncertainty in Container Shipping: Deep Reinforcement Learning for Enabling Adaptive and Feasible Master Stowage Planning
Feb 19, 2025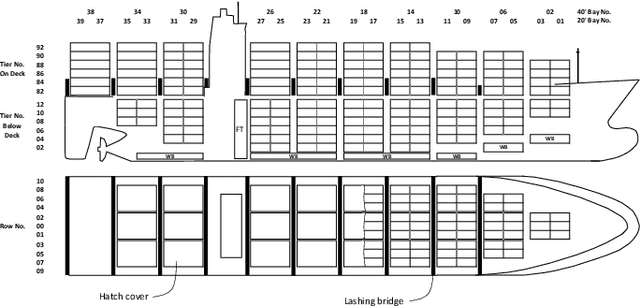
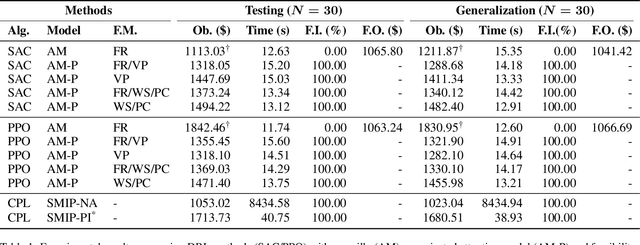
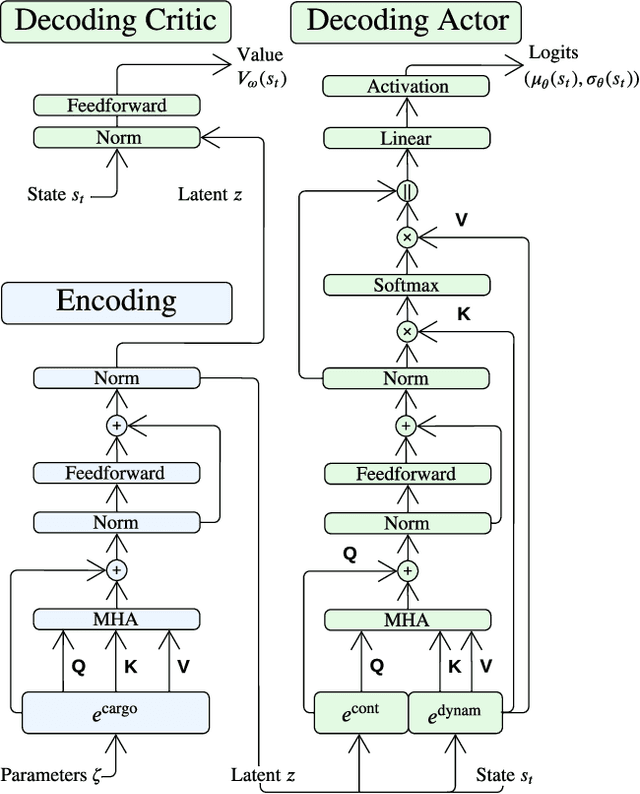

Reinforcement learning (RL) has shown promise in solving various combinatorial optimization problems. However, conventional RL faces challenges when dealing with real-world constraints, especially when action space feasibility is explicit and dependent on the corresponding state or trajectory. In this work, we focus on using RL in container shipping, often considered the cornerstone of global trade, by dealing with the critical challenge of master stowage planning. The main objective is to maximize cargo revenue and minimize operational costs while navigating demand uncertainty and various complex operational constraints, namely vessel capacity and stability, which must be dynamically updated along the vessel's voyage. To address this problem, we implement a deep reinforcement learning framework with feasibility projection to solve the master stowage planning problem (MPP) under demand uncertainty. The experimental results show that our architecture efficiently finds adaptive, feasible solutions for this multi-stage stochastic optimization problem, outperforming traditional mixed-integer programming and RL with feasibility regularization. Our AI-driven decision-support policy enables adaptive and feasible planning under uncertainty, optimizing operational efficiency and capacity utilization while contributing to sustainable and resilient global supply chains.
Fair Resource Allocation in Weakly Coupled Markov Decision Processes
Nov 14, 2024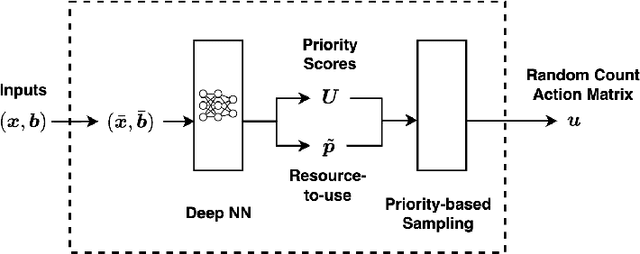
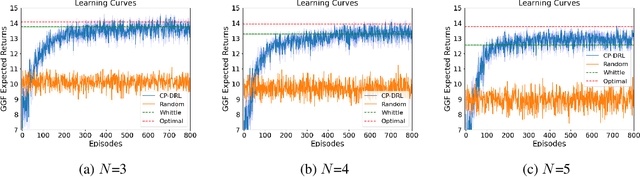

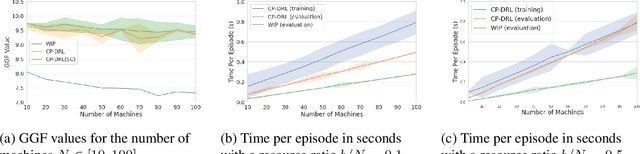
We consider fair resource allocation in sequential decision-making environments modeled as weakly coupled Markov decision processes, where resource constraints couple the action spaces of $N$ sub-Markov decision processes (sub-MDPs) that would otherwise operate independently. We adopt a fairness definition using the generalized Gini function instead of the traditional utilitarian (total-sum) objective. After introducing a general but computationally prohibitive solution scheme based on linear programming, we focus on the homogeneous case where all sub-MDPs are identical. For this case, we show for the first time that the problem reduces to optimizing the utilitarian objective over the class of "permutation invariant" policies. This result is particularly useful as we can exploit Whittle index policies in the restless bandits setting while, for the more general setting, we introduce a count-proportion-based deep reinforcement learning approach. Finally, we validate our theoretical findings with comprehensive experiments, confirming the effectiveness of our proposed method in achieving fairness.
Planning and Learning in Risk-Aware Restless Multi-Arm Bandit Problem
Oct 30, 2024In restless multi-arm bandits, a central agent is tasked with optimally distributing limited resources across several bandits (arms), with each arm being a Markov decision process. In this work, we generalize the traditional restless multi-arm bandit problem with a risk-neutral objective by incorporating risk-awareness. We establish indexability conditions for the case of a risk-aware objective and provide a solution based on Whittle index. In addition, we address the learning problem when the true transition probabilities are unknown by proposing a Thompson sampling approach and show that it achieves bounded regret that scales sublinearly with the number of episodes and quadratically with the number of arms. The efficacy of our method in reducing risk exposure in restless multi-arm bandits is illustrated through a set of numerical experiments.
Retail Analytics in the New Normal: The Influence of Artificial Intelligence and the Covid-19 Pandemic
Nov 27, 2023The COVID-19 pandemic has severely disrupted the retail landscape and has accelerated the adoption of innovative technologies. A striking example relates to the proliferation of online grocery orders and the technology deployed to facilitate such logistics. In fact, for many retailers, this disruption was a wake-up call after which they started recognizing the power of data analytics and artificial intelligence (AI). In this article, we discuss the opportunities that AI can offer to retailers in the new normal retail landscape. Some of the techniques described have been applied at scale to adapt previously deployed AI models, whereas in other instances, fresh solutions needed to be developed to help retailers cope with recent disruptions, such as unexpected panic buying, retraining predictive models, and leveraging online-offline synergies.